


Python: Python高并发编程
- TAGS: Python
Python 多进程与线程高并发编程
主要内容:
- 理解进程与线程
- 创建多线程
- 线程的属性
- 后台线程
- 事件 Event
- 线程锁、加锁、解锁策略
- 可重入锁
- Condition 和 生产者消费者模型
- 信号量通信 Semaphore
- 创建进程和池
- 僵尸进程、孤儿进程和守护进程
- 高级线程池、进程池异步库
- GIL全局解释器锁原理
- 多进程、多线程应用场景
并发
并发和并行区别
并行,parallel
- 同时做某些事,可以互不干扰的同一个时刻做几件事
并发,concurrency
- 也是同时做某些事,但是强调,一个时段内有事情要处理。
举例
- 高速公路的车道,双向4车道,所有车辆(数据)可以互不干扰的在自己的车道上奔跑(传输)
- 在同一个时刻,每条车道上可能同时有车辆在跑,是同时发生的概念,这是并行
- 在一段时间内,有这么多车要通过,这是并发
并发的解决
"食堂打饭模型"
中午12点,开饭啦,大家都涌向食堂,这就是并发。如果人很多,就是高并发
某个时间段内,数据涌来,这就是并发。如果数据量很大,就是 高并发
1、队列、缓冲区
假设只有一个窗口,陆续涌入食堂的人,排队打菜是比较好的方式。所以,排队(队列)是一种天然解决并发的办法。
排队就是把人排成 队列,先进先出,解决了资源使用的问题。排成的队列,其实就是一个缓冲地带,就是 缓冲区
假设女生优先,每次都从这个队伍中优先选出女生出来先打饭,这就是 优先队列
例如queue模块的类Queue、LifoQueue、PriorityQueue(小顶堆实现)
2、争抢
只开一个窗口,有可能没有秩序,也就是谁挤进去就给谁打饭。
挤到窗口的人占据窗口,直到打到饭菜离开。
其他人继续争抢,会有一个人占据着窗口,可以视为锁定窗口,窗口就不能为其他人提供服务了。这是一种 锁机制 。
谁抢到资源就上锁,排他性的锁,其他人只能等候。
争抢也是一种高并发解决方案,但是,这样可能不好,因为有可能有人很长时间抢不到。
3、预处理
其实排队长不是问题,就算2万人排成一队等吃饭,如果能10分钟搞定也行。问题就是在处理并发的速度太慢了。
经过分析发现,本食堂主要是打菜等候时间矿长,因为每个人都是现场点菜现做。
食堂可以提前统计大多数人最爱吃的菜品,将最爱吃的80%的热门菜,提前做好,保证供应,20%的冷门菜,现做。
这样大多数人,就算锁定窗口,也很快打到饭菜走了,快速释放窗口。
一种提前加载用户需要的数据的思路, 预处理 思想,缓存常用。
4、并行
成百上千人同时来吃饭,一个队伍搞不定的,多开打饭窗口形成多个队列,如同开多个车道一样,并行打菜。
开窗口就得扩大食堂,得多雇人在每一个窗口提供服务,造成 成本上升 。就高速公路一样,多车道是并行 方案,多车道提高了通行效率,但是也意味着建造维护成本也高了。
日常可以通过购买更多服务器,或多开进程、线程实现并行处理,来解决并发问题。
注意这些都是 水平扩展 思想。
并行是解决并发的手段之一。
注:
- 如果线程在单CPU上处理,就不是真并行了
- 但是多数服务器都是多CPU的,服务的部署往往是多机的、分布式的,这都是并行处理
5、提速
提高单个窗口的打饭速度,也是解决并发的方式。
打饭人员提高工作技能,或为单个窗口配备更多的服务人员,都是提速的办法。
提高单个CPU性能,或单个服务器安装更多的CPU。
这是一种 垂直扩展 思想
6、消息中间件
常见的消息中间件有RabbitMQ、ActiveMQ(Apache)、RocketMQ(阿里Apache)、kafka(Apache)等。
当然还有其他手段解决并发问题,但是已经列举除了最常用的解决方案,一般来说不同的并发场景用不同的策略,而策略可能是多种方式的优化组合
例如多开食堂(多地),也可以把食堂建设到宿舍生活区(就近),所以说,技术来源于生活。
queue模块–队列
queue模块的类Queue、LifoQueue、PriorityQueue三个类。
Queue
Queue是先进先出(first-in first-out)队列。
queue.Queue(maxsize=0)
- 创建FIFO队列,返回Queue对象
- maxsize小于等于0,队列长度没有限制
Queue.get(block=True, timeout=None)
- 从队列中移除元素并返回这个元素
- block为阻塞,timeout为超时
- 如果block为True,就阻塞,timeout为None就是一直阻塞。
- 如果block为True,但是timeout有值,就阻塞到一定秒数抛出Empty异常
- block为False,是非阻塞,timeout将被忽略,要么成功返回一个元素,要么抛出empty异常。
Queue.get_nowait()
- 等价于get(False),也就是说要么成功返回一个元素,要么抛出empty异常
- 但是queue的这种阻塞效果,需要多线程来演示
Queue.put(item, block=True, timeout=None)
- 把一个元素加入到队列中去
- block=True, timeout=None,一直阻塞到有空位放元素
- block=True, timeout=5,阻塞5秒就抛出Full异常
- block=False, timeout失效,立即返回,能塞进去就塞,不能则返回抛出Full异常。
Queue.put_nowait(item)
- 等价于put(item, False),也就是能塞进去就塞,不能则返回抛出Full异常。
范例:
from queue import Queue import time # 添加导入time模块 q = Queue() #尾部加入,头部拿走 q.put(1) q.put(2) q.put(3) print(q.get()) print(q.get()) #print(q.empty()) #判断队列是否为空,空返回False, 非空返回True print() time.sleep(1) print(q.get()) # print(q.get()) #队列有数据,立即获取;没有数据,默认阻塞等待。使用多线程解决 # print(q.get(timeout=5)) #等了5s,空手而归,抛出Empty异常 # print(q.get(False)) #我不等,有拿走,没有数据我也不等,空手而归,抛出异常Empty #返回结果 # 1 # 2 # 3
队列有数据,立即获取;没有数据,默认阻塞等待。使用多线程解决
from queue import Queue import time import threading q = Queue() #尾部加入,头部拿走 q.put(1) q.put(2) q.put(3) print(q.get()) print(q.get()) print(q.get()) def put_data(): time.sleep(5) print('~' * 30) q.put('test') t = threading.Thread(target=put_data) t.start() #启动线程 print(q.get()) #队列有数据,立即获取;没有数据,默认阻塞等待。使用多线程解决 print('-' * 30) #返回结果 # 1 # 2 # 3 # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # test # ------------------------------
from queue import Queue q = Queue(5) #尾部加入,头部拿走 q.put(1) q.put(2) q.put(3) q.put(4) print(q.full()) q.put(5) print(q.full(), q.qsize()) # q.put(6) #队列满了,默认永久阻塞,直到有空间为止 # q.put(6, True, timeout=3) #如果有空间,加入;否则等3秒,3秒后加入不成功抛异常 queue.Full #q.put(6, False) #能加入就立即加入到队列;如果满了,不等待,抛Full异常 q.put_nowait(6) #等价于q.put(6, False) print('-' * 30)
LifoQueue
后进先出队列,这个类继承自Queue,使用方式同Queue。
范例:
from queue import Queue, LifoQueue q = LifoQueue(5) #采用什么数据结构? list 本身就是栈,也可以链表实现 q.put(1) q.put(2) q.put(3) print(q.get()) print(q.get()) print(q.get()) #返回结果 # 3 # 2 # 1
源码
class LifoQueue(Queue): '''Variant of Queue that retrieves most recently added entries first.''' def _init(self, maxsize): self.queue = [] def _qsize(self): return len(self.queue) def _put(self, item): self.queue.append(item) def _get(self): return self.queue.pop() #覆盖了Queue类中的方法 class Queue: def put(self, item, block=True, timeout=None): with self.not_full: ... ... self._put(item) def _init(self, maxsize): self.queue = deque() #Queue使用的是双端队列 def _put(self, item): self.queue.append(item)
PriorityQueue
优先队列,这个类也继承自Queue类,并重写入队、出队的方法。
- 它里面是堆,用列表实现的堆,构建的是小顶堆。
- 元素可以存储任意值,但是优先队列内部是直接进行元素大小比较的,不同类型比较可能抛异常
- 入队时,将元素加入到列表末尾。然后进行小顶堆调整。
- 出队时,将索引0即堆顶处最小值弹出,然后将最后一个元素放到堆顶,重新堆调整。
from queue import Queue, LifoQueue, PriorityQueue q = PriorityQueue() #小顶堆,元素必须可以比较 q.put(1) q.put(2) # q.put('tom') # 报错,TypeError: '<' not supported between instances of 'str' and 'int' print(q.get()) print(q.get()) #返回结果 # 1 # 2
自定义类
from queue import Queue, LifoQueue, PriorityQueue class Student: def __init__(self, name, gender='M'): self.name = name self.gender = gender def __eq__(self, other): print('__eq__', self.name, other.name) return self.name == other.name and self.gender == other.gender def __lt__(self, other): # print('__lt__', self.name, other.name) s1 = "{}:{}".format(self.gender, self.name) #F:Alice s2 = "{}:{}".format(other.gender, other.name) return s1 < s2 def __repr__(self) -> str: return '<{} {}>'.format(self.name, self.gender) q = PriorityQueue() #小顶堆,元素必须可以比较 for name in ('tom', 'jerry', 'kite', 'sam', 'ben'): q.put(Student(name)) q.put(Student('Alice', 'F')) print(q.qsize()) for i in range(5): print(q.get()) #返回结果 # 6 # <Alice F> # <ben M> # <jerry M> # <kite M> # <sam M>
线程
进程和线程
线程
- 在实现了线程的操作系统中,线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一个程序的执行实例就是一个进程。
进程
- 进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是 系统进行资源分配和调度的基本单位 ,是操作系统结构的基础。
进程和程序的关系
- 程序是源代码编译后的文件,而这些文件存放在磁盘上。当程序被操作系统加载到内存中,就是进程,进程中存放着指令和数据(资源), 它也是线程的容器 。
Linux进程有父进程、子进程,Windows的进程是平等关系。
线程,有时被称为轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元。
一个标准的线程由线程ID,当前指令指针(PC)、寄存器集合和堆栈组成。
在许多系统中,创建一个线程比创建一个进程快10-100倍。
进程、线程的理解
现代操作系统提出进程的概念,每一个进程都认为自己独占所有的计算机硬件资源。
进程就是独立的王国,进程间不可以随便的共享数据。
线程就是省份,同一个进程内的线程可以共享进程的资源,每一个线程拥有自己独立的堆栈。
线程的状态
就绪(Ready)
线程能够运行,但在等待被调度。可能线程刚刚创建启动,或刚刚从阻塞中恢复,或者被其他线程抢占
运行(Running)
线程正在运行
阻塞(Blocked)
线程等待外部事件发生而无法运行,如I/O操作
终止(Terminated)
线程完成,或退出,或被取消
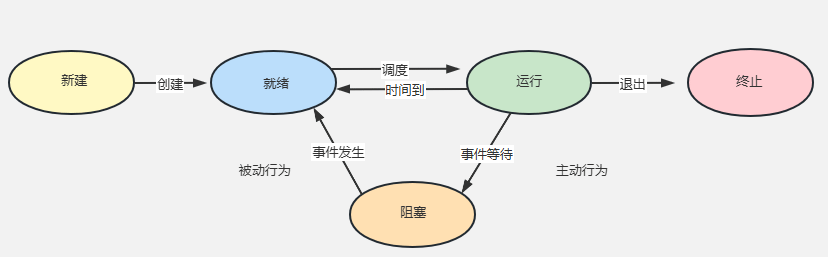
Python中的进程和线程
进程会启动一个解释器进程,线程共享一个解释器进程
Python的线程开发
Python的线程开发使用标准库threading。
进程靠线程执行代码,至少有一个 主线程 ,其它线程是工作线程
主线程是第一个启动的线程
父线程:如果线程A中启动了一个线程B,A就是B的父线程
子线程:B就是A的子线程
import threading def worker(): print("I'm a working") pass print("Finished") t = threading.Thread(target=worker, ) #创建一个线程对象,此线程未运行。主线程 t.start() #启动一个线程 #返回结果 # I'm a working # Finished
Thread类
def __init__(self, group=None, target=None, name=None,args=(), kwargs=None, *, daemon=None) #target 线程调用的对象,就是目标函数 #name 为线程起个名字 #args 为目标函数传递实参,元组 #kwargs 为目标函数关键字传参,字典
线程启动
import threading # 最简单的线程程序 def worker(): print("I'm working") print("Fineshed") t = threading.Thread(target=worker, name='worker') # 线程对象 t.start() # 启动
通过threading.Thread创建一个线程对象,target是目标函数,可以使用name为线程指定名称 但是线程没有启动,需要调用start方法 线程之所以执行函数,是因为线程中就是要执行代码的,而最简单的封装就是函数,所以还是函数调用 函数执行完,线程也就退出了 无线循环,不让线程退出
import threading import time def worker(): while True: time.sleep(1) print("I'm working") print("Fineshed") t = threading.Thread(target=worker, name='worker') # 线程对象 t.start() # 启动
线程退出
Python没有提供线程退出的方法,线程在下面情况时退出
- 线程函数内语句执行完毕
- 线程函数中抛出未处理的异常
import threading import time def worker(): count = 0 while True: if count > 5: # raise RuntimeError(count) # 抛异常 # return #函数返回 break time.sleep(1) count += 1 print("I'm working") print("Fineshed") t = threading.Thread(target=worker, name='worker') t.start() print("===end===")
Python的线程没有优先级、没有线程组的概念,也不能被销毁、停止、挂起,那也就没有恢复、中断了。
线程传参
import threading import time def add(x, y): print('{} + {} = {}'.format(x, y, x + y), threading.current_thread().ident) t1 = threading.Thread(target=add, name='add1', args=(4, 5)) t1.start() time.sleep(2) t2 = threading.Thread(target=add, name='add2', args=(6,), kwargs={'y':7}) t2.start() time.sleep(2) t3 = threading.Thread(target=add, name='add3', kwargs={'x':8, 'y':9}) t3.start() #返回结果 # 4 + 5 = 9 11048 # 6 + 7 = 13 15672 # 8 + 9 = 17 21196
线程传参和函数传参没什么区别,本质上就是函数传参
threading的属性和方法
current_thread() 返回当前线程对象 main_thread() 返回主线程对象 active_count() 当前处于alive状态的线程个数 enumerate() 返回所有活着的线程的列表,不包括已经终止的线程和未开始的线程 get_ident() 返回当前线程的ID,非0整数
import threading import time def showtreainfo(): print(threading.main_thread(), threading.current_thread(), threading.active_count(), threading.enumerate()) def worker(): showtreainfo() # 显示线程信息 #while True: for i in range(5): time.sleep(1) print('i am working') print('finished') t = threading.Thread(target=worker, name='worker') # 线程对象 showtreainfo() # 显示线程信息 time.sleep(1) t.start() # 启动运行一个线程 print('===enb===') #返回结果 # <_MainThread(MainThread, started 24000)> <_MainThread(MainThread, started 24000)> 1 [<_MainThread(MainThread, started 24000)>] # <_MainThread(MainThread, started 24000)> <Thread(worker, started 16948)> 2 [<_MainThread(MainThread, started 24000)>, <Thread(worker, started 16948)>] # ===enb=== # i am working # i am working # i am working # i am working # i am working # finished
active_count、enumerate方法返回的值还包括主线程
Thread实例的属性和方法
name 只是一个名字,只是个标识,名称可以重名。getName()、setName()获取、设置这个名词 ident 线程ID,它是非0整数。线程启动后才会有ID,否则为None。线程退出,此ID依旧可以访问。此ID可以重复使用 is_alive() 返回线程是否活着
注意:线程的name这是一个名称,可以重复;ID必须唯一,但可以在线程退出后再利用
范例:
import threading import time def worker(count, name): c = threading.current_thread() print(c.name, c.ident, '~~~~', t1, t1 is c) #t1, c是一个线程对象 while True: # for i in range(count): time.sleep(1) print('{} working'.format(name)) count += 1 if count > 3: break print('Finished') t1 = threading.Thread(target=worker, name='worker1', args=(0, 'w1')) print(t1.name, t1.ident, t1.is_alive(), '++++') #线程没有被创建是没有线程id的 time.sleep(1) t1.start() #启动一个线程 time.sleep(1) print(t1.name, t1.ident, t1.is_alive(), '----') #线程被创建后有线程id print('==end==') time.sleep(8) #当前线程等待8秒, print(t1.name, t1.ident, t1.is_alive(), '****') #线程被创建后有线程id #返回结果 # worker1 None False ++++ # worker1 25968 ~~~~ <Thread(worker1, started 25968)> True # worker1 25968 True ---- # w1 working # ==end== # w1 working # w1 working # w1 working # Finished # worker1 25968 False ****
import threading import time def worker(count, name): c = threading.current_thread() print(c.name, c.ident, '~~~~', t1, t1 is c) #t1, c是一个线程对象 while True: # for i in range(count): time.sleep(1) print('{} working'.format(name)) count += 1 if count > 3: break #1/0 print('Finished') t1 = threading.Thread(target=worker, name='worker1', args=(0, 'w1')) time.sleep(1) t1.start() #启动一个线程 time.sleep(1) print('==end==') while True: #主线程 time.sleep(1) print('{} {} {}'.format( t1.name, t1.ident,'alive' if t1.is_alive() else 'dead')) if not t1.is_alive(): print('{} restart'.format(t1.name)) t1.start() # RuntimeError: threads can only be started once #start方法对同一个线程对象只能用一次 #返回结果 # worker1 22548 ~~~~ <Thread(worker1, started 22548)> True # w1 working # ==end== # w1 working # worker1 22548 alive # w1 working # worker1 22548 alive # w1 working # Finished # worker1 22548 dead # worker1 restart # Traceback (most recent call last): # File "d:\project\pyproj\cursor\t2.py", line 30, in <module> # t1.start() # RuntimeError: threads can only be started once # ~~~~~~~~^^ # File "D:\py\py313\Lib\threading.py", line 967, in start # raise RuntimeError("threads can only be started once") # RuntimeError: threads can only be started once
- start() 启动线程。每一个线程必须且只能执行该方法一次
- run() 运行线程函数
start()方法会调用run()方法,而run()方法可以运行函数。
- start和run的区别
import threading import time class MyThread(threading.Thread): def start(self) -> None: #override 在这里除了覆盖,还要调用父类的同名方法 print('start~~~~') super().start() def run(self) -> None: print('run~~~~') super().run() def worker(count, name): print(threading.enumerate()) # while True: for i in range(3): time.sleep(1) print('{} working'.format(name)) print('Finished') t1 = MyThread(target=worker, name='worker1', args=(0, 'w1')) time.sleep(1) # t1.start() #启动一个线程 -> 会调用run方法,并行。start必须产生一个操作系统的真正的新线程。 #start会阻塞吗?没有,因为它会立即返回。 t1.run() #直接调用run方法. 和start方法一样只能用一次。串行执行. 只有一个线程,主。核心调用了target方法。 #run 不会产生线程。在一个线程内,程序一定是按顺序执行的,不可以并行。 print('==end==') #直接调用run方法返回结果 # run~~~~ # [<_MainThread(MainThread, started 29348)>] # w1 working # w1 working # w1 working # Finished # ==end== #start方法返回结果 # start~~~~ # run~~~~ # ==end== # [<_MainThread(MainThread, started 9192)>, <MyThread(worker1, started 14192)>] # w1 working # w1 working # w1 working # Finished
- 使用start方法启动线程,启动了一个新的线程,名字叫做worker运行。
- 但是使用run方法的,并没有启动新的线程,就是在主线程中调用了一个普通的函数而已。
因此,启动线程请使用start方法,且对于这个线程来说,start方法只能调用一次。(设置_started属性实现)
多线程
顾名思义,多个线程,一个进程中如果有多个线程运行,就是多线程,实现一种并发。
import threading import time def worker(): t = threading.current_thread() for i in range(5): time.sleep(1) print('i an working', t.name, t.ident) print('finished') class MyTread(threading.Thread): def start(self) -> None: print('start~~~~~') super().start() def run(self): print('run~~~~~') super().run() t1 = MyTread(target=worker, name='worker1') t2 = MyTread(target=worker, name='worker2') t1.start() t2.start() #返回结果 # start~~~~~ # run~~~~~ # start~~~~~ # run~~~~~ # i an working worker1 28736 # i an working worker2 27012 # i an working worker1 28736 # i an working worker2 27012 # i an working worker2 27012 # i an working worker1 28736 # i an working worker1 28736 # i an working worker2 27012 # i an working worker1 28736 # finished # i an working worker2 27012 # finished
可以看到worker1和work2交替执行,改成run方法试试看
import threading import time def worker(): t = threading.current_thread() for i in range(5): time.sleep(1) print('i an working', t.name, t.ident) print('finished') class MyTread(threading.Thread): def start(self) -> None: print('start~~~~~') super().start() def run(self): print('run~~~~~') super().run() t1 = MyTread(target=worker, name='worker1') t2 = MyTread(target=worker, name='worker2') # t1.start() # t2.start() t1.run() t2.run() #返回结果 # run~~~~~ # i an working MainThread 5904 # i an working MainThread 5904 # i an working MainThread 5904 # i an working MainThread 5904 # i an working MainThread 5904 # finished # run~~~~~ # i an working MainThread 5904 # i an working MainThread 5904 # i an working MainThread 5904 # i an working MainThread 5904 # i an working MainThread 5904 # finished
没有开新的线程,这就是普通函数调用,所以执行完t1.run(),然后执行t2.run(),这里就不是多线程。
当使用start方法启动线程后,进程内有多个活动的线程并行的工作,就是多线程。
一个进程中至少有一个线程,并作为程序的入口,这个线程就是 主线程 。
一个进程至少有一个主线程。
其他线程称为 工作线程
daemon线程和non-daemon线程
注意:有人翻译成后台线程,也有人翻译成守护进程。
Python中,构造线程的时候,可以设置daemon属性,这个属性必须在start方法前设置好。
# 源码Thread的__init__方法中 if daemon is not None: self._daemonic = daemon # 用户设定bool值 else: self._daemonic = current_thread().daemon
线程daemon属性,如果设定就是用户的设置,否则就取当前线程的daemon值。
主线程是non-daemon线程,即daemon = False。
class _MainThread(Thread): def __init__(self): Thread.__init__(self, name="MainThread", daemon=False)
import threading import time def worker(name, interval=1): for i in range(5): time.sleep(interval) print('{} working'.format(name)) t = threading.Thread(target=worker, args=('t1', 1)) t.start() print('==end==') #返回结果 # ==end== # t1 working # t1 working # t1 working # t1 working # t1 working
发现线程t依然执行,主线程已经执行完,但是一直等着线程t。
修改为 t = threading.Thread(target=foo, daemon=True)
程序立即结束了,主线程根本没有等线程t。
daemon属性 表示线程是否是daemon线程,这个值必须在start()之前设置,否则引发RuntimeError异常
isDaemon() 是否是daemon线程
setDaemon 设置为daemon线程,必须在start方法之前设置
观察下面代码主线程何时结束daemon线程
import threading import time def worker(name, interval=1): print(name, 'enter~~~~') time.sleep(interval) print('{} working ++++'.format(name)) t1 = threading.Thread(target=worker, name='t1', args=('t1', 1), daemon=True) #False non-daemon 线程,等到该线程结束进程结束;True daemon # print(t1.daemon, t1.isDaemon()) # t1.daemon = False # t1.setDaemon(False) #和t1.daemon = False 效果一样 t1.start() # t1.setDaemon(True) #错,必须放在start之前 t2 = threading.Thread(target=worker, name='t2', args=('t2', 5), daemon=False) t2.start() print('==end==') #主线程结束了,无事可做 print(*threading.enumerate(), sep='\n') #唯一non-daemon线程主线程无事可做, #返回结果 # t1 enter~~~~ # t2 enter~~~~ # ==end== # <_MainThread(MainThread, started 25192)> # <Thread(t1, started daemon 19144)> # <Thread(t2, started 11740)> # t1 working ++++ # t2 working ++++
上例说明,如果除主线程之外还有non-daemon线程的时候,主线程退出时,也不 会杀掉所有daemon线程,直到所有non-daemon线程全部结束,如果还有daemon线 程,主线程需要退出(主线程退出也可以理解为最后一个non-daemon线程也要退 出了),会结束所有daemon线程,程序退出。
总结
- 线程具有一个daemon属性,可以手动设置为True或False,也可以不设置,则取默认值None。
- 如果不设置daemon,就取当前线程的daemon来设置它。
- 主线程是non-daemon线程,即daemon = False。
- 从主线程创建的所有线程的不设置daemon属性,则默认都是daemon = False,也就是non-daemon线程。
- Python程序在没有活着的non-daemon线程运行时,程序退出,也就是除主线程 之外剩下的只能都是daemon线程,主线程才能退出,否则主线程就只能等待。
join方法
import threading import time def foo(name, timeout): time.sleep(timeout) print('{} working'.format(name)) t1 = threading.Thread(target=foo, args=('t1', 5), daemon=True) # 调换5和10看看效果 t1.start() t1.join()# 永久阻塞,到t1线程线束运行 print('Main Thread Exits') # 执行结果 t1 working Main Thread Exits
- 使用了join方法后,daemon线程执行完了,主线程才退出了
- 如果取消join方法,主线程执行完直接退出
import threading import time def foo(name, timeout): time.sleep(timeout) print('{} working'.format(name)) t1 = threading.Thread(target=foo, args=('t1', 5), daemon=True) # 调换5和10看看效果 t1.start() t1.join(2) #主线程等了2秒,阻塞 print('~~~~~~~~~~~') t1.join(2) print('~~~~~~~~~~~') print('Main Thread Exits') # 执行结果 ~~~~~~~~~~~ ~~~~~~~~~~~ Main Thread Exits
join(timeout=None),是线程的标准方法之一
- 一个线程中调用另一个线程的join方法,调用者将被阻塞,直到被调用线程终止,或阻塞超时。
- 一个线程可以被join多次。
- timeout参数指定调用者等待多久,没有设置超时,就一直等到被调用线程结束。
- 调用谁的join方法,就是join谁,就要等谁。
daemon线程应用场景
简单来说就是,本来并没有 daemon thread,为了简化程序员的工作,让他们不 用去记录和管理那些后台线程,创造了一个 daemon thread 的概念。这个概念 唯一的作用就是,当你把一个线程设置为 daemon,它可以会随主线程的退出而 退出
主要应用场景有:
- 后台任务。如发送心跳包、监控,这种场景最多。
- 主线程工作才有用的线程。如主线程中维护这公共的资源,主线程已经清理了,准备退出,而工作线程使用这些资源工作也没有意义了,一起退出最合适
- 随时可以被终止的线程
如果主线程退出,想所有其它工作线程一起退出,就使用daemon=True来创建工作线程。
比如,开启一个线程定时判断WEB服务是否正常工作,主线程退出,工作线程也 没有必须存在了,应该随着主线程退出一起退出。这种daemon线程一旦创建,就 可以忘记它了,只用关心主线程什么时候退出就行了。
daemon线程,简化了程序员手动关闭线程的工作
如果在non-daemon线程A中,对另一个daemon线程B使用了join方法,这个线程B 设置成daemon就没有什么意义了,因为non-daemon线程A总是要等待B。
如果在一个daemon线程C中,对另一个daemon线程D使用了join方法,只能说明C 要等待D,主线程退出,C和D不管是否结束,也不管它们谁等谁,都要被杀掉。
范例:
import threading import time def worker2(name): while True: time.sleep(1) print('{} working'.format(name), threading.current_thread().isDaemon()) def worker1(name): current = threading.current_thread() print("{}'s daemon = {}".format(name, current.isDaemon())) t2 = threading.Thread(target=worker2, args=('t2',), name='t2') # 隐式 daemon=True,继承自t1 t2.start() t1 = threading.Thread(target=worker1, args=('t1',), daemon=True, name='t1') t1.start() time.sleep(4) print('Main Thread Exits') print(threading.active_count(), threading.enumerate()) # 执行结果 # t1 s daemon = True # t2 working True # t2 working True # t2 working True # Main Thread Exits # 2 [<_MainThread(MainThread, started 29620)>, <Thread(t2, started daemon 28036)>]
上例,只要主线程要退出,2个工作线程都结束
使用join,让线程不结束
import threading import time def worker2(name): while True: time.sleep(1) print('{} working'.format(name), threading.current_thread().isDaemon()) def worker1(name): current = threading.current_thread() print("{}'s daemon = {}".format(name, current.isDaemon())) t2 = threading.Thread(target=worker2, args=('t2',), name='t2', daemon=True) # 隐式 daemon=True,继承自t1 t2.start() t2.join() #阻塞,等待t2结束 t1 = threading.Thread(target=worker1, args=('t1',), daemon=True, name='t1') t1.start() t1.join() #阻塞,等待t1结束 time.sleep(4) print('Main Thread Exits') print(threading.active_count(), threading.enumerate())
threading.local类
import time import threading import logging FORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s" logging.basicConfig(format=FORMAT, level=logging.INFO, datefmt="%Y-%m-%d %H:%M:%S") def worker(): x = 0 #x 非常安全 for i in range(1000): time.sleep(0.00001) x += 1 logging.info("x = {}".format(x)) for i in range(10): threading.Thread(target=worker, name='w{}'.format(i)).start() #返回结果 # 2025-03-05 23:51:11 w3 14560 x = 1000 # 2025-03-05 23:51:11 w0 2604 x = 1000 # 2025-03-05 23:51:11 w6 11708 x = 1000 # 2025-03-05 23:51:11 w2 5260 x = 1000 # 2025-03-05 23:51:11 w9 4248 x = 1000 # 2025-03-05 23:51:11 w4 12032 x = 1000 # 2025-03-05 23:51:11 w5 8992 x = 1000 # 2025-03-05 23:51:11 w8 13044 x = 1000 # 2025-03-05 23:51:11 w1 15524 x = 1000 # 2025-03-05 23:51:11 w7 12520 x = 1000
上例使用多线程,每个线程完成不同的计算任务。
x是局部变量,可以看出每一个线程的x是独立的,互不干扰的
- 改造成全局变量
import time import threading import logging FORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s" logging.basicConfig(format=FORMAT, level=logging.INFO, datefmt="%Y-%m-%d %H:%M:%S") class A: def __init__(self): self.x = 0 # 全局对象 global_data = A() # x = 0 def worker(): # global x for i in range(1000): time.sleep(0.00001) global_data.x += 1 # x += 1 logging.info("x = {}".format(global_data.x)) for i in range(10): threading.Thread(target=worker, name='w{}'.format(i)).start() #返回结果 # 2025-03-05 23:46:45 w0 12256 x = 9916 # 2025-03-05 23:46:45 w3 13540 x = 9943 # 2025-03-05 23:46:45 w2 12872 x = 9962 # 2025-03-05 23:46:45 w5 3256 x = 9966 # 2025-03-05 23:46:45 w1 5032 x = 9969 # 2025-03-05 23:46:45 w4 4720 x = 9985 # 2025-03-05 23:46:45 w6 4188 x = 9991 # 2025-03-05 23:46:45 w7 5152 x = 9995 # 2025-03-05 23:46:45 w9 16268 x = 9999 # 2025-03-05 23:46:45 w8 17668 x = 10000
上例虽然使用了全局对象,但是线程之间互相干扰,导致了不期望的结果。 线程不安全 。
能不能既使用全局对象,还能保持每个线程使用不同的数据呢?
通过这个例子可以看到,使用了多线程导致结果完全不确定,原因在A类上,我们称这个 线程不安全 。
线程安全
- 多线程执行一段代码,不产生不确定的结果,那这段代码就是线程安全的。
python提供threading.local 类,将这个类实例化得到一个全局对象,但是不同的线程使用这个对象存储的数据。其他线程看不见。
import time import threading import logging FORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s" logging.basicConfig(format=FORMAT, level=logging.INFO, datefmt="%Y-%m-%d %H:%M:%S") # 全局对象 global_data = threading.local() def worker(): global_data.x = 0 for i in range(1000): time.sleep(0.00001) global_data.x += 1 logging.info("x = {}".format(global_data.x)) for i in range(10): threading.Thread(target=worker, name='w{}'.format(i)).start() #返回结果 # 2025-03-06 00:01:48 w2 14064 x = 100 # 2025-03-06 00:01:48 w4 7008 x = 1000 # 2025-03-06 00:01:48 w8 3540 x = 1000 # 2025-03-06 00:01:48 w1 19008 x = 100 # 2025-03-06 00:01:48 w7 14404 x = 100 # 2025-03-06 00:01:48 w6 1564 x = 1000 # 2025-03-06 00:01:48 w0 14412 x = 100 # 2025-03-06 00:01:48 w3 18144 x = 100 # 2025-03-06 00:01:48 w5 872 x = 1000 # 2025-03-06 00:01:48 w9 3496 x = 1000
结果显示和使用局部变量的效果一样。
- 再看threading.local的例子
import threading import time X = 'abc' global_data = threading.local() # 注意这个对象所处的线程 global_data.x = 100 #threading.local 对象, 属性创建在什么线程,什么线程可用 print(global_data, type(global_data), global_data.x) def worker(): print(X) print(global_data) # print(global_data.x) # AttributeError: '_thread._local' object has no attribute 'x' print('in worker') worker() print('-' * 30) threading.Thread(target=worker).start() # 执行结果 # <_thread._local object at 0x0000022C6D77E938> <class '_thread._local'> 100 # abc # <_thread._local object at 0x0000022C6D77E938> # in worker # ------------------------------ # abc # <_thread._local object at 0x0000022C6D77E938> # in worker
- 再另外一个线程中执行print(global_data.x)会抛AttributeError: '_thread._local' object has no attribute 'x'错误,但是global_data打印没有出错,说明看到global_data,而global_data中的x看不到,所以这个x不能跨线程。
- threading.local类构建了一个大字典,存放所有线程相关的字典,定义如下:
{ id(Thread) -> (ref(Thread), thread-local dict) }- 每一线程实例的id为key,元组为value, value中2部分为,线程对象引用,每个线程自己的字典
本质
- 运行时,threading.local实例处在不同的线程中,就从大字典中找到当前线程相关键值对中的字典,覆盖threading.local实例的
__dict__ - 这样就可以在不同的线程中,安全地使用线程独有的数据,做到了线程间数据隔离,如同本地变量一样安全
threading.local()源码解读
#local源码 class _localimpl: """A class managing thread-local dicts""" __slots__ = 'key', 'dicts', 'localargs', 'locallock', '__weakref__' def __init__(self): self.key = '_threading_local._localimpl.' + str(id(self)) # { id(Thread) -> (ref(Thread), thread-local dict) } self.dicts = {} def get_dict(self): """Return the dict for the current thread. Raises KeyError if none defined.""" thread = current_thread() return self.dicts[id(thread)][1] def create_dict(self): """Create a new dict for the current thread, and return it.""" localdict = {} key = self.key thread = current_thread() idt = id(thread) def local_deleted(_, key=key): thread = wrthread() if thread is not None: del thread.__dict__[key] def thread_deleted(_, idt=idt): local = wrlocal() if local is not None: dct = local.dicts.pop(idt) wrlocal = ref(self, local_deleted) wrthread = ref(thread, thread_deleted) thread.__dict__[key] = wrlocal self.dicts[idt] = wrthread, localdict return localdict class local: __slots__ = '_local__impl', '__dict__' def __new__(cls, /, *args, **kw): if (args or kw) and (cls.__init__ is object.__init__): raise TypeError("Initialization arguments are not supported") self = object.__new__(cls) impl = _localimpl() impl.localargs = (args, kw) impl.locallock = RLock() object.__setattr__(self, '_local__impl', impl) # We need to create the thread dict in anticipation of # __init__ being called, to make sure we don't call it # again ourselves. impl.create_dict() return self def __getattribute__(self, name): with _patch(self): return object.__getattribute__(self, name) def __setattr__(self, name, value): if name == '__dict__': raise AttributeError( "%r object attribute '__dict__' is read-only" % self.__class__.__name__) with _patch(self): return object.__setattr__(self, name, value) def __delattr__(self, name): if name == '__dict__': raise AttributeError( "%r object attribute '__dict__' is read-only" % self.__class__.__name__) with _patch(self): return object.__delattr__(self, name)
class local: __slots__ = '_local__impl', '__dict__' def __new__(cls, /, *args, **kw): 创建local的实例并返回 local实例创建了一个属性 setattr(self, 'xxx', value) 等价self.xxx =value 都是要使用该类型定义的 __setattr__方法,本质调用基类的该方法,让他帮你完成属性的设置。 local实例创建了_local__impl属性,是_localimpl实例(key, dicts{}) impl.create_dict() return self def __getattribute__(self, name): with _patch(self): return object.__getattribute__(self, name) def __setattr__(self, name, value): if name == '__dict__': raise AttributeError( "%r object attribute '__dict__' is read-only" % self.__class__.__name__) with _patch(self): return object.__setattr__(self, name, value) class _localimpl: """A class managing thread-local dicts""" __slots__ = 'key', 'dicts', 'localargs', 'locallock', '__weakref__' def __init__(self): self.key = '_threading_local._localimpl.' + str(id(self)) self.dicts = {} def get_dict(self): """Return the dict for the current thread. Raises KeyError if none defined.""" thread = current_thread() return self.dicts[id(thread)][1] def create_dict(self): """Create a new dict for the current thread, and return it.""" localdict = {} #本地字典 key = self.key #str(id(self)) thread = current_thread() #当前线程对象 idt = id(thread) #线程对象的地址 def local_deleted(_, key=key): thread = wrthread() if thread is not None: del thread.__dict__[key] def thread_deleted(_, idt=idt): local = wrlocal() if local is not None: dct = local.dicts.pop(idt) wrlocal = ref(self, local_deleted) #关联引来 wrthread = ref(thread, thread_deleted) #关联引来 thread.__dict__[key] = wrlocal #当前线程对象字典中增加 self.key #当前线程.[str(id(impl))] = self.dicts[idt] = wrthread, localdict #大字典 # {id(currentthread): (, {})} return localdict @contextmanager #上下文使用函数,yeild之前相当于enter,yeild返回as def _patch(self): #self是local实例 impl = object.__getattribute__(self, '_local__impl') try: dct = impl.get_dict() #self.dicts[id(currentthread)][1] except KeyError: dct = impl.create_dict() #为当前线程创建小字典 args, kw = impl.localargs self.__init__(*args, **kw) with impl.locallock: object.__setattr__(self, '__dict__', dct) #在local对象上做小字典的切换 yield #-------- import threading import logging import time FORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s" logging.basicConfig(format=FORMAT, level=logging.INFO, datefmt="%Y-%m-%d %H:%M:%S") g_data = threading.loacl() #属性_local__impl -> imple() key, dicts{} #大字典中有一个小字典和主线程相关 def worker(): g_data.x = 0 # x 属性和线程相关,用工作线程的地址 for i in range(1000): time.sleep(0.0001) g_data.x += 1 logging.info("x = {}".format(g_data.x)) for i in range(10): threading.Thread(target=worker, name='w{}'.format(i), ).start()
线程同步
概念
线程同步,线程间协同,通过某种技术,让一个线程访问某些数据时,其他线程不能访问这些数据,直到该线程完成对数据的操作。
Event***
Event事件,是线程间通信机制中最简单的实现,使用一个内部的标记flag,通过flag的True或False的变化来进行操作。
set() 标记设置为True clear() 标记设置为False is_set() 标记是否为True wait(timeout=None) 设置等待标记为True的时长,None为无限等待。等到返回True,未等到超时了返回False
import threading from threading import Event import time e = Event() print(e) print(e.is_set()) #False print(e.wait(1)) #阻塞1秒,如果不写会一直等待
import threading from threading import Event import time def fn(e:Event): time.sleep(2) e.set() #1 e = Event() print(e) print(e.is_set()) threading.Thread(target=fn,args=(e,)).start() print(e.wait(5)) #阻塞5秒, 这里等了2秒 e.clear() #清空事件
练习
老板雇佣了一个工人,让他生产杯子,老板一直等着这个工人,直到生产了10个杯子
import threading from threading import Event import time import logging FORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s" logging.basicConfig(format=FORMAT,level=logging.INFO) cups = [] flag = False def boss(): logging.info("I'm boss, waiting for you") while not flag: #轮询 time.sleep(0.5) logging.info("Good job.") def worker(count=10): logging.info('I\'m worker for you') # cups = [] global flag while len(cups) < count: time.sleep(0.5) cups.append(1) logging.info('made one cup') flag = True #注意这里 logging.info('Finished my job') b = threading.Thread(target=boss, name='boss') w = threading.Thread(target=worker, name='worker') b.start() w.start() #返回结果 # 2025-03-07 14:06:30,864 boss 29476 I'm boss, waiting for you # 2025-03-07 14:06:30,865 worker 11820 I'm worker for you # 2025-03-07 14:06:31,366 worker 11820 made one cup # 2025-03-07 14:06:31,866 worker 11820 made one cup # 2025-03-07 14:06:32,367 worker 11820 made one cup # 2025-03-07 14:06:32,869 worker 11820 made one cup # 2025-03-07 14:06:33,369 worker 11820 made one cup # 2025-03-07 14:06:33,871 worker 11820 made one cup # 2025-03-07 14:06:34,372 worker 11820 made one cup # 2025-03-07 14:06:34,873 worker 11820 made one cup # 2025-03-07 14:06:35,374 worker 11820 made one cup # 2025-03-07 14:06:35,875 worker 11820 made one cup # 2025-03-07 14:06:35,876 worker 11820 Finished my job # 2025-03-07 14:06:36,370 boss 29476 Good job.
使用Event
import threading from threading import Event import time import logging FORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s" logging.basicConfig(format=FORMAT,level=logging.INFO) cups = [] event = Event() def boss(e:Event): logging.info("I'm boss, waiting for you") e.wait() #一直等,等到0->1 logging.info("Good job.") def worker(e:Event, count=10): logging.info('I\'m worker for you') # cups = [] global flag while len(cups) < count: time.sleep(0.5) cups.append(1) logging.info('made one cup') e.set() #0 -> 1 logging.info('Finished my job') b = threading.Thread(target=boss, name='boss1', args=(event,)) w = threading.Thread(target=worker, name='worker', args=(event,)) b.start() threading.Thread(target=boss, name='boss2', args=(event,)).start() w.start() #返回结果 # 2025-03-07 14:23:11,029 boss1 25008 I'm boss, waiting for you # 2025-03-07 14:23:11,029 boss2 14672 I'm boss, waiting for you # 2025-03-07 14:23:11,029 worker 29412 I'm worker for you # 2025-03-07 14:23:11,530 worker 29412 made one cup # 2025-03-07 14:23:12,031 worker 29412 made one cup # 2025-03-07 14:23:12,532 worker 29412 made one cup # 2025-03-07 14:23:13,033 worker 29412 made one cup # 2025-03-07 14:23:13,533 worker 29412 made one cup # 2025-03-07 14:23:14,035 worker 29412 made one cup # 2025-03-07 14:23:14,536 worker 29412 made one cup # 2025-03-07 14:23:15,038 worker 29412 made one cup # 2025-03-07 14:23:15,538 worker 29412 made one cup # 2025-03-07 14:23:16,039 worker 29412 made one cup # 2025-03-07 14:23:16,040 worker 29412 Finished my job # 2025-03-07 14:23:16,040 boss2 14672 Good job. # 2025-03-07 14:23:16,040 boss1 25008 Good job.
总结
- 需要使用同一个Event对象的标记flag
- 谁wait就是等到flag变为True,或等到超时返回False
- 不限制等待的个数,通知所有等待者
wait的使用
import threading from threading import Event import time import logging FORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s" logging.basicConfig(format=FORMAT,level=logging.INFO) cups = [] event = threading.Event() def worker(e:Event, count=10): logging.info('I\'m worker for you') while not event.wait(0.5): #每次等0.5秒执行 # time.sleep(0.5) # event.wait(0.5) cups.append(1) logging.info('made one cup') if len(cups) >= count: event.set() # break logging.info('Finished my job') w = threading.Thread(target=worker, name='worker', args=(event,)) w.start()
或者
def worker(e:Event, count=10): logging.info('I\'m worker for you') while not event.is_set(): #每次等0.5秒执行 time.sleep(0.5) # event.wait(0.5) cups.append(1) logging.info('made one cup') if len(cups) >= count: event.set() # break logging.info('Finished my job')
定时器 Timer/延迟执行
threading.Timer继承自Thread,这个类用来定义延迟多久后执行一个函数
class threading.Timer(interval, function, args=None, kwargs=None)
start方法执行之后,Timer对象会处于等待状态,等待了interval秒之后,开始执行function函数的
from threading import Timer #定时器 import time def worker(name): print('{} is working'.format(name)) time.sleep(1) print('finished') t = Timer(3, worker, args=('tom',)) #定时器,延迟3秒执行 # t.cancel() #取消定时器, 在start前,后面start无效。 t.start() # t.cancel() #取消定时器 print('==main exit==')
上例代码工作线程早就启动了,只不过是在工作线程中延时了3秒才执行了worker函数
Timer是线程Thread的子类,Timer实例内部提供了一个finished属性,该属性是 Event对象。cancel方法,本质上是在worker函数执行前对finished属性set方法 操作,从而跳过了worker函数执行,达到了取消的效果
总结:
- Timer是线程Thread的子类,就是线程类,具有线程的能力和特征
- 它的实例是能够延时执行目标函数的线程,在真正执行目标函数之前,都可以cancel它
- cancel方法本质使用Event类实现。这并不是说,线程提供了取消的方法
Lock***
锁,一旦线程获得锁,其它试图获取锁的线程将被阻塞。
锁:凡是存在共享资源争抢的地方都可以使用锁,从而保证只有一个使用者可以完全使用这个资源
acquire(blocking=True, timeout=-1) 默认阻塞,阻塞可以设置超时时间。非阻塞时,timeout禁止设置 成功获取锁,返回True,否则返回False release() 释放锁。可以从任何线程调用释放 已上锁的锁,会被重置为unlocked未上锁的锁上调用,抛RuntimeError异常
锁的基本使用
import threading import time from threading import Timer lock = threading.Lock() x = lock.acquire() #True 拿到了 print(x) y = lock.acquire(timeout=2) #拿到锁后,再拿,如果没有timeout,会一直等待 print(y) z = lock.acquire(False) #非阻塞 print(z) # print(lock.acquire(False, timeout=2)) #报错ValueError。非阻塞不可以设置超时 lock.release() #释放锁 #返回结果 # True # False # False
import threading l = threading.Lock() print(l.acquire(False)) print(l.acquire(False)) #返回结果 #True #False
import threading import time from threading import Timer import logging FORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s" logging.basicConfig(format=FORMAT, level=logging.INFO) lock = threading.Lock() x = lock.acquire() #True 拿到了 print(x) def worker(l:threading.Lock): name = threading.current_thread().name print(name, 'want to get locker') logging.info(l.acquire()) print(name, 'finished') #lock.release() #释放 for i in range(5): threading.Thread(target=worker, name='w{}'.format(i), args=(lock,)).start() while True: time.sleep(1) cmd = input('>>>').strip() if cmd == 'r': lock.release() elif cmd == 'quit': break else: print(threading.enumerate())
True w0 want to get locker w1 want to get locker w2 want to get locker w3 want to get locker w4 want to get locker >>> [<_MainThread(MainThread, started 19956)>, <Thread(w0, started 13524)>, <Thread(w1, started 18416)>, <Thread(w2, started 16556)>, <Thread(w3, started 12748)>, <Thread(w4, started 2396)>] >>>r 2025-03-09 11:49:13,210 w0 13524 True w0 finished >>>r 2025-03-09 11:49:44,730 w1 18416 True w1 finished >>>r 2025-03-09 11:49:59,880 w2 16556 True w2 finished >>>r 2025-03-09 11:50:01,878 w3 12748 True w3 finished >>>r 2025-03-09 11:50:04,629 w4 2396 True w4 finished >>> [<_MainThread(MainThread, started 19956)>] >>>r >>>r Traceback (most recent call last): File "d:\project\pyprojs\cursor\t.py", line 28, in <module> lock.release() ~~~~~~~~~~~~^^ RuntimeError: release unlocked lock
上例可以看出不管在哪一个线程中,只要对一个已经上锁的锁阻塞请求,该线程就会阻塞。
练习
订单要求生产1000个杯子,组织10个工人生产。请忽略老板,关注工人生成杯子
import threading import time from threading import Timer import logging FORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s" logging.basicConfig(format=FORMAT, level=logging.INFO) lock = threading.Lock() cups = [] def worker(l:threading.Lock, count=1000): logging.info('{} is working'.format(threading.current_thread().name)) while len(cups) < count: time.sleep(0.0001) cups.append(1) # logging.info('made one') logging.info('{} finishe. cups={}'.format(threading.current_thread().name, len(cups))) for i in range(5): threading.Thread(target=worker, name='w{}'.format(i), args=(lock, 1000)).start() #返回结果 # 2025-03-09 16:24:33,671 w0 3844 w0 is working # 2025-03-09 16:24:33,672 w1 21328 w1 is working # 2025-03-09 16:24:33,673 w2 21200 w2 is working # 2025-03-09 16:24:33,673 w3 20700 w3 is working # 2025-03-09 16:24:33,674 w4 20072 w4 is working # 2025-03-09 16:24:33,787 w0 3844 w0 finishe. cups=1000 # 2025-03-09 16:24:33,788 w4 20072 w4 finishe. cups=1001 # 2025-03-09 16:24:33,788 w3 20700 w3 finishe. cups=1002 # 2025-03-09 16:24:33,788 w1 21328 w1 finishe. cups=1003 # 2025-03-09 16:24:33,788 w2 21200 w2 finishe. cups=1004
为什么多生产了? 多线程调度,导致了判断失效,多生产了杯子。如何修改?加锁。
import threading import time from threading import Timer import logging FORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s" logging.basicConfig(format=FORMAT, level=logging.INFO) lock = threading.Lock() cups = [] def worker(l:threading.Lock, count=1000): logging.info('{} is working'.format(threading.current_thread().name)) flag = False while True: l.acquire() #加锁 if len(cups) >= count: flag = True # l.release() #1释放锁? 线程不安全, time.sleep(0.001) #为了看出线程切换效果 if not flag: cups.append(1) l.release() #2释放锁? if flag: break # l.release() #3释放锁? 会死锁。 flag=True 时,会死锁。 logging.info('{} finishe. cups={}'.format(threading.current_thread().name, len(cups))) for i in range(5): threading.Thread(target=worker, name='w{}'.format(i), args=(lock, )).start() #返回结果 # 2025-03-09 16:54:13,637 w0 6896 w0 is working # 2025-03-09 16:54:13,638 w1 5812 w1 is working # 2025-03-09 16:54:13,639 w2 21308 w2 is working # 2025-03-09 16:54:13,640 w3 11152 w3 is working # 2025-03-09 16:54:13,640 w4 1556 w4 is working # 2025-03-09 16:54:15,417 w4 1556 w4 finishe. cups=1000 # 2025-03-09 16:54:15,419 w0 6896 w0 finishe. cups=1000 # 2025-03-09 16:54:15,421 w2 21308 w2 finishe. cups=1000 # 2025-03-09 16:54:15,423 w3 11152 w3 finishe. cups=1000 # 2025-03-09 16:54:15,424 w1 5812 w1 finishe. cups=1000
上例中共有三处可以释放锁。只有第二出释放锁的位置正确
假设位置1的lock.release()合适,分析如下:
有一个时刻,在某一个线程中len(cups)正好是999,flag=True,释放锁,正好 线程被打断。另一个线程判断发现也是999,flag=True,可能线程被打断。可能 另外一个线程也判断是999,flag也设置为True。这三个线程只要继续执行到 cups.append(1),一定会导致cups的长度超过1000的。
假设位置2的lock.release()合适,分析如下:
在某一个时刻len(cups),正好是999,flag=True,其它线程试图访问这段代码 的线程都阻塞获取不到锁,直到当前线程安全的增加了一个数据,然后释放锁。 其它线程有一个抢到锁,但发现已经1000了,只好break打印退出。再其它线程 都一样,发现已经1000了,都退出了。
所以位置2 释放锁 是正确的。
但是我们发现锁保证了数据完整性,但是性能下降很多。
上例中位置3,if flag:break是为了保证位置2的release方法被执行,否则,就出现了死锁,得到锁的永远没有释放锁。
计数器类,可以加,可以减。
#t.py文件 class Balancer: def __init__(self): self._value = 0 def inc(self): self._value += 1 def dec(self): self._value -= 1 @property def value(self): return self._value def run(c:Balancer, count=100): for i in range(count): for j in range(-50, 50): if j < 0: c.dec() else: c.inc() #t2.py from t import Balancer, run import threading c = Balancer() threads = 10 count = 1000 #10 结果是0,100结果是0, 1000结果是? 可能时间片用完 #多个线程中用到同一个对象,可能会导致数据不一致 for i in range(threads): threading.Thread( target=run, args=(c, count), name='balancer-{}'.format(i) ).start() print(c.value) #返回结果 可能是0 可能是其他
#t.py文件 import threading class Balancer: def __init__(self): self._value = 0 self.__lock = threading.Lock() def inc(self): self.__lock.acquire() try: self._value += 1 finally: self.__lock.release() def dec(self): with self.__lock: self._value -= 1 @property def value(self): with self.__lock: return self._value #需要加锁吗? def run(c:Balancer, count=100): for i in range(count): for j in range(-50, 50): if j < 0: c.dec() else: c.inc() #t2.py文件 from t import Balancer, run import threading c = Balancer() threads = 10 count = 1000 #10 结果是0,100结果是0, 1000结果是? 可能时间片用完 #多个线程中用到同一个对象,可能会导致数据不一致 for i in range(threads): threading.Thread( target=run, args=(c, count), name='balancer-{}'.format(i) ).start() print(c.value) #结果是 -128 -139 .. 为什么? 主线程提前读了
之所以读属性的时候也要加锁,原因在于,如果不加锁,那么就可以读取到脏数据。例如写法 in, 它修改了一次数据,这是临时的修改,如果出现了异常,这个数据一定不算数。
#t.py文件 import threading class Balancer: def __init__(self): self._value = 0 self.__lock = threading.Lock() def inc(self): self.__lock.acquire() try: self._value += 1 finally: self.__lock.release() def dec(self): with self.__lock: self._value -= 1 @property def value(self): with self.__lock: return self._value #需要加锁吗? def run(c:Balancer, count=100): for i in range(count): for j in range(-50, 50): if j < 0: c.dec() else: c.inc() #t2.py文件 from t import Balancer, run import threading import time c = Balancer() threads = 10 count = 1000 #10 结果是0,100结果是0, 1000结果是? 可能时间片用完 #多个线程中用到同一个对象,可能会导致数据不一致 for i in range(threads): threading.Thread( target=run, args=(c, count), name='balancer-{}'.format(i) ).start() while True: time.sleep(2) if threading.active_count() == 1: print(c.value) break else: print(threading.enumerate())
返回结果
[<_MainThread(MainThread, started 19780)>, <Thread(balancer-1, started 22952)>, <Thread(balancer-2, started 2412)>, <Thread(balancer-3, started 22220)>, <Thread(balancer-4, started 24804)>, <Thread(balancer-5, started 6336)>, <Thread(balancer-6, started 24836)>, <Thread(balancer-7, started 20036)>, <Thread(balancer-8, started 24124)>, <Thread(balancer-9, started 23072)>] [<_MainThread(MainThread, started 19780)>, <Thread(balancer-1, started 22952)>, <Thread(balancer-2, started 2412)>, <Thread(balancer-3, started 22220)>, <Thread(balancer-4, started 24804)>, <Thread(balancer-5, started 6336)>, <Thread(balancer-6, started 24836)>, <Thread(balancer-7, started 20036)>, <Thread(balancer-8, started 24124)>, <Thread(balancer-9, started 23072)>] 0
对于同一个数据,多个线程争着写入,一般来说都需要加锁,保证只有一个线程能够写入,直到 成功写入,释放锁。
加锁、解锁
一般来说,加锁就需要解锁,但是加锁后解锁前,还要有一些代码执行,就有可 能抛异常,一旦出现异常,锁是无法释放,但是当前线程可能因为这个异常被终 止了,这也产生了死锁。
加锁、解锁常用语句:
- 使用try…finally语句保证锁的释放
- with上下文管理,锁对象支持上下文管理
锁的应用场景
锁适用于访问和修改同一个共享资源的时候,即读写同一个资源的时候。
如果全部都是读取同一个共享资源不需要加锁,因为这时可以认为共享资源是不可变的,每一次读取它都是一样的值,所以不用加锁。
使用锁的注意事项:
- 少用锁,必要时用锁。使用了锁,多线程访问被锁的资源时,就成了串行,要么排队执行,要么争抢执行
- 举例,高速公路上车并行跑,可是到了省界只开放了一个收费口,过了这个 口,车辆依然可以在多车道上一起跑。过收费口的时候,如果排队一辆辆过, 加不加锁一样效率相当,但是一旦出现争抢,就必须加锁一辆辆过。注意, 不管加不加锁,只要是一辆辆过,效率就下降了
- 加锁时间越短越好,不需要就立即释放锁
- 一定要避免死锁
不使用锁,有了效率,但是结果是错的。
使用了锁,效率低下,但是结果是对的。
但是为了保证数据的正确性,必要时还是得需要使用锁。
非阻塞锁使用
可重入锁RLock
可重入锁,是线程相关的锁。
线程A获得可重复锁,并可以多次成功获取,不会阻塞。最后要在线程A中做和acquire次数相同的release。
import threading l = threading.RLock() print(l.acquire()) print(l.acquire()) print(l.release()) print(l.release()) # print(l.release()) #报错。拿几次锁,就要释放几次锁 #返回结果 # True # True # None # None # Traceback (most recent call last): # File "d:\project\pyprojs\cursor\t2.py", line 10, in <module> # print(l.release()) # ~~~~~~~~~^^ # RuntimeError: cannot release un-acquired lock
import threading import time from threading import Timer import logging FORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s" logging.basicConfig(format=FORMAT, level=logging.INFO) print(threading.get_ident(), '++++') lock = threading.RLock() logging.info('{} {}'.format(lock.acquire(), lock)) #True logging.info('-' * 30) logging.info('{} {}'.format(lock.acquire(), lock)) #True def worker(l): logging.info('in worker~~~~') logging.info(threading.get_ident()) logging.info(l) logging.info(l.acquire()) logging.info(l) logging.info(l.acquire()) logging.info(l) logging.info('get one lock') t = threading.Thread(target=worker, name='woker', args=(lock,)) t.start() time.sleep(3) logging.info('1 {} {}'.format(lock.release(), lock)) time.sleep(2) logging.info('2 {} {}'.format(lock.release(), lock)) time.sleep(5) logging.info(lock) logging.info(lock.acquire()) #现在锁属性woker中,内部没有释放,这里就会一直等待 logging.info('=' * 30) #返回结果 # 24540 ++++ # 2025-03-09 22:56:50,943 MainThread 24540 True <locked _thread.RLock object owner=24540 count=1 at 0x000001E9ECC3A080> # 2025-03-09 22:56:50,944 MainThread 24540 ------------------------------ # 2025-03-09 22:56:50,944 MainThread 24540 True <locked _thread.RLock object owner=24540 count=2 at 0x000001E9ECC3A080> # 2025-03-09 22:56:50,945 woker 5720 in worker~~~~ # 2025-03-09 22:56:50,946 woker 5720 5720 # 2025-03-09 22:56:50,946 woker 5720 <locked _thread.RLock object owner=24540 count=2 at 0x000001E9ECC3A080> # 2025-03-09 22:56:53,946 MainThread 24540 1 None <locked _thread.RLock object owner=24540 count=1 at 0x000001E9ECC3A080> # 2025-03-09 22:56:55,947 MainThread 24540 2 None <unlocked _thread.RLock object owner=0 count=0 at 0x000001E9ECC3A080> # 2025-03-09 22:56:55,947 woker 5720 True # 2025-03-09 22:56:55,948 woker 5720 <locked _thread.RLock object owner=5720 count=1 at 0x000001E9ECC3A080> # 2025-03-09 22:56:55,949 woker 5720 True # 2025-03-09 22:56:55,949 woker 5720 <locked _thread.RLock object owner=5720 count=2 at 0x000001E9ECC3A080> # 2025-03-09 22:56:55,950 woker 5720 get one lock # 2025-03-09 22:57:00,949 MainThread 24540 <locked _thread.RLock object owner=5720 count=2 at 0x000001E9ECC3A080> #卡这里了
可重入锁总结
- 与线程相关,可在一个线程中获取锁,并可继续在同一线程中不阻塞多次获取锁
- 当锁未释放完,其它线程获取锁就会阻塞,直到当前持有锁的线程释放完锁
- 锁都应该使用完后释放。可重入锁也是锁,应该acquire多少次,就release多少次
Condition
构造方法 Condition(lock=None),可以传入一个Lock或RLock对象,默认是RLock。
acquire(*args) 获取锁 wait(self, timeout=None) 等待或超时 notify(n=1) 唤醒至多指定数目个数的等待的线程,没有等待的线程就没有任何操作 notify_all() 唤醒所有等待的线程
Condition基本使用
范例:一个工人生产1000个杯子,有2个老板等到他生产完为止。
import threading import time import logging FORMAT = '%(asctime)s %(threadName)s %(thread)d %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) # event = threading.Event() cond = threading.Condition() def boss(): logging.info('I am watching u') # event.wait() with cond: logging.info('我等') cond.wait() logging.info('Good job') def worker(count=1000): logging.info('Starting......') cups = [] while len(cups) < count: time.sleep(0.0001) cups.append(1) with cond: #cond.notify_all() # 通知所有等待的线程 cond.notify(2) # 通知2个线程. 1对1 单播; 1对多, 多播,广播,1对全体 logging.info('finished. cups={}'.format(len(cups))) # event.set() b1 = threading.Thread(target=boss, name='b1') b2 = threading.Thread(target=boss, name='b2') b1.start() b2.start() w = threading.Thread(target=worker, name='worker') w.start() #返回结果 # 2025-03-10 10:24:25,399 b1 21400 I am watching u # 2025-03-10 10:24:25,399 b1 21400 我等 # 2025-03-10 10:24:25,399 b2 25884 I am watching u # 2025-03-10 10:24:25,399 b2 25884 我等 # 2025-03-10 10:24:25,399 worker 27616 Starting...... # 2025-03-10 10:24:25,954 worker 27616 finished. cups=1000 # 2025-03-10 10:24:25,954 b2 25884 Good job # 2025-03-10 10:24:25,954 b1 21400 Good job
Condition用于生产者、消费者模型,为了解决生产者消费者速度匹配问题
下例只是为了演示,不考虑线程安全问题
import threading from threading import Thread, Event, Condition import time import logging import random FORMAT = '%(asctime)s %(threadName)s %(thread)d %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) #生产者消费者模型 class Dispatcher: def __init__(self): self.data = None def produce(self): logging.info('starting...') while True: time.sleep(1) # 模拟生产速度 self.data = random.randint(1, 50) logging.info( self.data) def consume(self): logging.info('consume...') while True: time.sleep(0.5) # 模拟消费速度。 最大的问题在于,消费者主动轮询获取数据 if self.data: data = self.data logging.info(self.data) self.data = None d = Dispatcher() p = threading.Thread(target=d.produce, name='producer') c = threading.Thread(target=d.consume, name='consumer') c.start() p.start() #返回结果 # 2025-03-10 10:42:25,185 consumer 24904 consume... # 2025-03-10 10:42:25,185 producer 11784 starting... # 2025-03-10 10:42:26,186 producer 11784 6 # 2025-03-10 10:42:26,687 consumer 24904 6 # 2025-03-10 10:42:27,187 producer 11784 30 # 2025-03-10 10:42:27,187 consumer 24904 30 # 2025-03-10 10:42:28,188 producer 11784 48 # 2025-03-10 10:42:28,188 consumer 24904 48 # 2025-03-10 10:42:29,188 producer 11784 39 # 2025-03-10 10:42:29,189 consumer 24904 39
import threading from threading import Thread, Event, Condition import time import logging import random FORMAT = '%(asctime)s %(threadName)s %(thread)d %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) #生产者消费者模型 class Dispatcher: def __init__(self): self.data = None self.event = threading.Event() self.cond = threading.Condition() def produce(self): logging.info('starting...') while not self.event.wait(1): #self.event.wait(1)不能放在with中 # time.sleep(1) # 模拟生产速度 self.data = random.randint(1, 50) logging.info( self.data) with self.cond: # self.cond.notify_all() self.cond.notify(2) def consume(self): logging.info('consume...') # while not self.event.wait(0.3): # time.sleep(0.5) # 模拟消费速度。 最大的问题在于,消费者主动轮询获取数据 while True: with self.cond: self.cond.wait() data = self.data logging.info(self.data) # self.data = None d = Dispatcher() p = threading.Thread(target=d.produce, name='producer') # 增加消费者 for i in range(5): c = threading.Thread(target=d.consume, name='consumer{}'.format(i)) c.start() p.start() #返回结果 # 2025-03-10 11:19:16,733 consumer0 14844 consume... # 2025-03-10 11:19:16,733 consumer1 11276 consume... # 2025-03-10 11:19:16,734 consumer2 16232 consume... # 2025-03-10 11:19:16,734 consumer3 21172 consume... # 2025-03-10 11:19:16,734 consumer4 27172 consume... # 2025-03-10 11:19:16,734 producer 26236 starting... # 2025-03-10 11:19:17,740 producer 26236 17 # 2025-03-10 11:19:17,741 consumer0 14844 17 # 2025-03-10 11:19:17,741 consumer1 11276 17 # 2025-03-10 11:19:18,751 producer 26236 1 # 2025-03-10 11:19:18,752 consumer3 21172 1 # 2025-03-10 11:19:18,752 consumer2 16232 1 # 2025-03-10 11:19:19,761 producer 26236 30 # 2025-03-10 11:19:19,762 consumer4 27172 30 # 2025-03-10 11:19:19,762 consumer0 14844 30 # 2025-03-10 11:19:20,767 producer 26236 49 # 2025-03-10 11:19:20,768 consumer1 11276 49 # 2025-03-10 11:19:20,768 consumer3 21172 49
这个例子,可以看到实现了消息的一对多 ,这其实就是广播模式。
注:上例中,程序本身不是线程安全的,程序逻辑有很多瑕疵,但是可以很好的帮助理解Condition的使用和生产者消费者模型。
Condition总结
- Condition用于生产者消费者模型中,解决生产者消费者速度匹配的问题
- 采用了通知机制,非常有效率
使用方式
- 使用Condition,必须先acquire,用完了要release,因为内部使用了锁,默认使用RLock锁,最好的方式是使用with上下文
- 消费者wait,等待通知
- 生产者生产好消息,对消费者发通知,可以使用notify或者notify_all方法
semaphore信号量
和Lock很像,信号量对象内部维护一个倒计数器,每一次acquire都会减1,当 acquire方法发现计数为0就阻塞请求的线程,直到其它线程对信号量release后, 计数大于0,恢复阻塞的线程。
Semaphore(value=1) 构造方法。value小于0,抛ValueError异常 acquire(blocking=True, timeout=None) 获取信号量,计数器减1,获取成功返回True release() 释放信号量,计数器加1
范例:
import threading from threading import Thread, Semaphore import time import logging import random FORMAT = '%(asctime)s %(threadName)s %(thread)d %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) #信号量 s = threading.Semaphore(3) logging.info(s.acquire()) logging.info(s._value) logging.info(s.acquire()) logging.info(s._value) logging.info(s.acquire()) logging.info(s._value) logging.info('----') s.release() #释放一个信号量 s.release() s.release() logging.info(s.__dict__) s.release() logging.info(s.__dict__) s.release() logging.info(s.__dict__) #返回结果 # 2025-03-10 15:25:31,454 MainThread 27692 True # 2025-03-10 15:25:31,455 MainThread 27692 2 # 2025-03-10 15:25:31,455 MainThread 27692 True # 2025-03-10 15:25:31,455 MainThread 27692 1 # 2025-03-10 15:25:31,455 MainThread 27692 True # 2025-03-10 15:25:31,455 MainThread 27692 0 # 2025-03-10 15:25:31,456 MainThread 27692 ---- # 2025-03-10 15:25:31,456 MainThread 27692 {'_cond': <Condition(<unlocked _thread.lock object at 0x000001ADBA3FE590>, 0)>, '_value': 3} # 2025-03-10 15:25:31,456 MainThread 27692 {'_cond': <Condition(<unlocked _thread.lock object at 0x000001ADBA3FE590>, 0)>, '_value': 4} # 2025-03-10 15:25:31,456 MainThread 27692 {'_cond': <Condition(<unlocked _thread.lock object at 0x000001ADBA3FE590>, 0)>, '_value': 5}
计数器永远不会低于0,因为acquire的时候,发现是0,都会被阻塞。
import threading from threading import Thread, Semaphore import time import logging import random FORMAT = '%(asctime)s %(threadName)s %(thread)d %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) #信号量 s = threading.Semaphore(3) logging.info(s.acquire()) logging.info(s._value) logging.info(s.acquire()) logging.info(s._value) logging.info(s.acquire()) logging.info(s._value) logging.info('----') def worker(): logging.info(s) logging.info(s.__dict__) logging.info(s.acquire()) # s.release() #释放一个信号量 logging.info('release s one time') logging.info(s.__dict__) threading.Timer(2, worker).start() time.sleep(3) # logging.info(s.acquire()) s.release() #释放一个信号量 logging.info(s.__dict__) logging.info('got it') #返回结果 # 2025-03-10 15:21:31,906 MainThread 28616 True # 2025-03-10 15:21:31,907 MainThread 28616 2 # 2025-03-10 15:21:31,907 MainThread 28616 True # 2025-03-10 15:21:31,907 MainThread 28616 1 # 2025-03-10 15:21:31,907 MainThread 28616 True # 2025-03-10 15:21:31,907 MainThread 28616 0 # 2025-03-10 15:21:31,908 MainThread 28616 ---- # 2025-03-10 15:21:33,923 Thread-1 22360 <threading.Semaphore at 0x1aeb5550590: value=0> # 2025-03-10 15:21:33,924 Thread-1 22360 {'_cond': <Condition(<unlocked _thread.lock object at 0x000001AEB551E390>, 0)>, '_value': 0} # 2025-03-10 15:21:34,908 MainThread 28616 {'_cond': <Condition(<unlocked _thread.lock object at 0x000001AEB551E390>, 0)>, '_value': 1} # 2025-03-10 15:21:34,909 MainThread 28616 got it # 2025-03-10 15:21:34,909 Thread-1 22360 True # 2025-03-10 15:21:34,910 Thread-1 22360 release s one time # 2025-03-10 15:21:34,910 Thread-1 22360 {'_cond': <Condition(<unlocked _thread.lock object at 0x000001AEB551E390>, 0)>, '_value': 0}
release方法超界问题
假设如果还没有acquire信号量,就release,会怎么样?
从上例输出结果可以看出,竟然内置计数器达到了5,这样实际上超出我们的最大值,需要解决这个问题
BoundedSemaphore类
有界的信号量,不允许使用release超出初始值的范围,否则,抛出ValueError异常
import threading from threading import Thread, Semaphore import time import logging import random FORMAT = '%(asctime)s %(threadName)s %(thread)d %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) #信号量 s = threading.BoundedSemaphore(3) #有界的信号量 logging.info(s.acquire()) logging.info(s._value) logging.info(s.acquire()) logging.info(s._value) logging.info(s.acquire()) logging.info(s._value) logging.info('----') s.release() #释放一个信号量 s.release() s.release() logging.info(s.__dict__) s.release() #超界了,报错 logging.info(s.__dict__) s.release() logging.info(s.__dict__) #返回结果 # 2025-03-10 15:35:55,695 MainThread 12376 True # 2025-03-10 15:35:55,695 MainThread 12376 2 # 2025-03-10 15:35:55,695 MainThread 12376 True # 2025-03-10 15:35:55,695 MainThread 12376 1 # 2025-03-10 15:35:55,695 MainThread 12376 True # 2025-03-10 15:35:55,695 MainThread 12376 0 # 2025-03-10 15:35:55,696 MainThread 12376 ---- # 2025-03-10 15:35:55,696 MainThread 12376 {'_cond': <Condition(<unlocked _thread.lock object at 0x0000021BFA58FC90>, 0)>, '_value': 3, '_initial_value': 3} # Traceback (most recent call last): # File "d:\project\pyproj\cursor\t.py", line 23, in <module> # s.release() # ~~~~~~~~~^^ # File "D:\py\py313\Lib\threading.py", line 576, in release # raise ValueError("Semaphore released too many times") # ValueError: Semaphore released too many times
应用举例
连接池
因为资源有限,且开启一个连接成本高,所以,使用连接池
一个简单的连接池
连接池应该有容量(总数),有一个工厂方法可以获取连接,能够把不用的连接返回,供其他调用者使用
class Conn: def __init__(self, name): self.name = name class Pool: def __init__(self, count:int): self.count = count # 池中提前放着连接备用 self.pool = [self._connect('conn-{}'.format(i)) for i in range(self.count)] def _connect(self, conn_name): # 创建连接的方法,返回一个连接对象 return Conn(conn_name) def get_conn(self): # 从池中拿走一个连接 if len(self.pool) > 0: return self.pool.pop() def return_conn(self, conn:Conn): # 向池中返回一个连接对象 self.pool.append(conn)
真正的连接池的实现比上面的例子要复杂的多,这里只是简单的一个功能的实现
本例中,get_conn()方法在多线程的时候有线程安全问题
假设池中正好有一个连接,有可能多个线程判断池的长度是大于0的,当一个线程拿走了连接对象,其他线程再来pop就会抛异常的。如何解决?
1、加锁,在读写的地方加锁
2、使用信号量Semaphore
范例:加锁方式,连接池
import threading from threading import Thread, Semaphore import time import logging import random FORMAT = '%(asctime)s %(threadName)s %(thread)d %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) #Pool 池,池中资源获得很不容易,但是我们用的很频繁,而且还要复用。 #连接池, 创建连接、维护连接非常消耗资源。线程池、进程池 class Conn: def __init__(self, name): self.name = name class Pool: def __init__(self, count:int=5): self.count = count # 池中提前放着连接备用 self.pool = [self._connect('conn-{}'.format(i)) for i in range(self.count)] self._lock = threading.Lock() def _connect(self, conn_name): # 创建连接的方法,返回一个连接对象 return Conn(conn_name) def get_conn(self): # 从池中拿走一个连接 with self._lock: if len(self.pool) > 0: return self.pool.pop() def return_conn(self, conn:Conn): # 向池中返回一个连接对象 with self._lock: self.pool.append(conn) # 初始化连接池 pool = Pool(3) def worker(pool:Pool): conn = pool.get_conn() logging.info(conn) # 模拟使用了一段时间 time.sleep(random.randint(1, 5)) pool.return_conn(conn) for i in range(6): threading.Thread(target=worker, name='worker-{}'.format(i), args=(pool,)).start() #返回结果 # 2025-03-10 17:29:55,987 worker-0 18212 <__main__.Conn object at 0x00000238B7D2EFD0> # 2025-03-10 17:29:55,988 worker-1 27588 <__main__.Conn object at 0x00000238B7D2EE90> # 2025-03-10 17:29:55,988 worker-2 23464 <__main__.Conn object at 0x00000238B7D36510> # 2025-03-10 17:29:55,988 worker-3 28380 None # 2025-03-10 17:29:55,989 worker-4 24136 None # 2025-03-10 17:29:55,989 worker-5 26188 None
范例:使用信号量对上例进行修改
import threading from threading import Thread, Semaphore import time import logging import random FORMAT = '%(asctime)s %(threadName)s %(thread)d %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) #Pool 池,池中资源获得很不容易,但是我们用的很频繁,而且还要复用。 #连接池, 创建连接、维护连接非常消耗资源。线程池、进程池 class Conn: def __init__(self, name): self.name = name class Pool: def __init__(self, count:int=5): self.count = count # 池中提前放着连接备用 self.pool = [self._connect('conn-{}'.format(i)) for i in range(self.count)] # self._lock = threading.Lock() # self.sema = threading.Semaphore(self.count) self.sema = threading.BoundedSemaphore(self.count) def _connect(self, conn_name): # 创建连接的方法,返回一个连接对象 return Conn(conn_name) def get_conn(self): # 从池中拿走一个连接 self.sema.acquire() return self.pool.pop() def return_conn(self, conn:Conn): # 向池中返回一个连接对象 self.pool.append(conn) self.sema.release() # 初始化连接池 pool = Pool(3) def worker(pool:Pool): conn = pool.get_conn() logging.info(conn) # 模拟使用了一段时间 time.sleep(random.randint(1, 5)) pool.return_conn(conn) for i in range(6): threading.Thread(target=worker, name='worker-{}'.format(i), args=(pool,)).start() #返回结果 # 2025-03-10 17:50:03,637 worker-0 28432 <__main__.Conn object at 0x000002C0718F7250> # 2025-03-10 17:50:03,637 worker-1 22796 <__main__.Conn object at 0x000002C0718F7110> # 2025-03-10 17:50:03,637 worker-2 26252 <__main__.Conn object at 0x000002C0719163C0> # 2025-03-10 17:50:06,638 worker-3 14912 <__main__.Conn object at 0x000002C0718F7110> # 2025-03-10 17:50:06,638 worker-4 25476 <__main__.Conn object at 0x000002C0719163C0> # 2025-03-10 17:50:07,638 worker-5 22960 <__main__.Conn object at 0x000002C0718F7250>
上例中,使用信号量解决资源有限的问题
如果池中有资源,请求者获取资源时信号量减1,拿走资源。当请求超过资源数, 请求者只能等待。当使用者用完归还资源后信号量加1,等待线程就可以被唤醒 拿走资源
注意:这个连接池的例子不能用到生成环境,只是为了说明信号量使用的例子,连接池还有很多未完成功能
问题
self.conns.append(conn) 这一句有哪些问题考虑?
1、边界问题分析
return_conn方法可以单独执行,有可能多归还连接,也就是会多release,所以,要用有界信号量
BoundedSemaphore类
这样用有界信号量修改源代码,保证如果多return_conn就会抛异常
self.pool.append(conn) self.semaphore.release()
假设一种极端情况,计数器还差1就归还满了,有三个线程A、B、C都执行了第一句,都没有来得及release,这时候轮到线程A release,正常的release,然后轮到线程C先release,一定出问题,超界了,直接抛异常
因此信号量,可以保证,一定不能多归还
如果归还了同一个连接多次怎么办,重复很容易判断
这个程序还不能判断这些连接是不是原来自己创建的,这不是生成环境用的代码,只是简单演示
2、正常使用分析
正常使用信号量,都会先获取信号量,然后用完归还
创建很多线程,都去获取信号量,没有获得信号量的线程都阻塞。能归还的线程都是前面获取到信号量的线程,其他没有获得线程都阻塞着。非阻塞的线程append后才release,这时候等待的线程被唤醒,才能pop,也就是没有获取信号量就不能pop,这是安全的
经过上面的分析,信号量比计算列表长度好,线程安全
信号量和锁
信号量,可以多个线程访问共享资源,但这个共享资源数量有限。
锁,可以看做特殊的信号量,即信号量计数器初值为1。只允许同一个时间一个线程独占资源。
Queue的线程安全
标准库queue模块,提供FIFO的Queue、LIFO的队列、优先队列。
Queue类是线程安全的,适用于多线程间安全的交换数据。内部使用了Lock和Condition。
为什么讲魔术方法时,说实现容器的大小,不准确?
如果不加锁,是不可能获得准确的大小的,因为你刚读取到了一个大小,还没有取走数据,就有可能 被其他线程改了。
Queue类的size虽然加了锁,但是,依然不能保证立即get、put就能成功,因为读取大小和get、put方法是分开的。
import queue q = queue.Queue(8) if q.qsize == 7: q.put() #上下两句可能被打断 if q.qsize == 1: q.get() #未必会成功
GIL全局解释器锁
参考文档:https://docs.python.org/3/glossary.html#term-GIL
CPython 解释器所采用的一种机制,它确保同一时刻只有一个线程在执行 Python bytecode。此机制通过设置对象模型(包括 dict 等重要内置类型)针 对并发访问的隐式安全简化了 CPython 实现。给整个解释器加锁使得解释器多 线程运行更方便,其代价则是牺牲了在多处理器上的并行性。
不过,某些标准库或第三方库的扩展模块被设计为在执行计算密集型任务如压缩或哈希时释放 GIL。 此外,在执行 I/O 操作时也总是会释放 GIL。
在 Python 3.13 中,GIL 可以使用 –disable-gil 构建配置选项来禁用。 在 使用此选项构建 Python 之后,代码必须附带 -X gil=0 或在设置 PYTHON_GIL=0 环境变量后运行。 此特性将为多线程应用程序启用性能提升并让 高效率地使用多核 CPU 更加容易。 要了解详情,请参阅 PEP 703。
CPython 在解释器进程级别有一把锁,叫做GIL,即全局解释器锁。
GIL 保证CPython进程中,只有一个线程执行字节码。甚至是在多核CPU的情况下,也只允许同时只能有一个CPU上运行该进程的一个线程。
CPython中
- IO密集型,某个线程阻塞,就会调度其他就绪线程
- CPU密集型,当前线程可能会连续的获得GIL,导致其它线程几乎无法使用CPU
- 在CPython中由于有GIL存在,IO密集型,使用多线程较为合算;CPU密集型,使用多进程,要绕开GIL
新版CPython正在努力优化GIL的问题,但不是移除。
如果在意多线程的效率问题,请绕行,选择其它语言erlang、Go等。
Python中绝大多数内置数据结构的读、写操作都是原子操作
由于GIL的存在,Python的内置数据类型在多线程编程的时候就变成了安全的了,但是实际上它们本身不是线程安全类型
保留GIL的原因
Guido坚持的简单哲学,对于初学者门槛低,不需要高深的系统知识也能安全、简单的使用Python。
而且移除GIL,会降低CPython单线程的执行效率。
测试下面2个程序,请问下面的程序是计算密集型还是IO密集型?
import threading import datetime import logging FORMAT = '%(asctime)s %(threadName)s %(thread)d %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) def calc(): sum = 0 for _ in range(100000000): #1亿 sum += 1 logging.info(sum) start = datetime.datetime.now() calc() calc() calc() calc() #纯串行 delta = (datetime.datetime.now() - start).total_seconds() print('串行 耗时={}s'.format(delta)) #返回结果 # 2025-03-10 23:24:49,646 MainThread 15556 100000000 # 2025-03-10 23:24:55,259 MainThread 15556 100000000 # 2025-03-10 23:25:00,528 MainThread 15556 100000000 # 2025-03-10 23:25:06,034 MainThread 15556 100000000 # 串行 耗时=22.13501s
下例为cpu密集型
不适合用多线程来使用。可以使用多进程
import threading import datetime import logging FORMAT = '%(asctime)s %(threadName)s %(thread)d %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) def calc(): sum = 0 for _ in range(100000000): #1亿 sum += 1 logging.info(sum) start = datetime.datetime.now() #并行,假并行,因为有GIL c1 = threading.Thread(target=calc, name='c1') c2 = threading.Thread(target=calc, name='c2') c3 = threading.Thread(target=calc, name='c3') c4 = threading.Thread(target=calc, name='c4') c1.start() c2.start() c3.start() c4.start() c1.join() c2.join() c3.join() c4.join() delta = (datetime.datetime.now() - start).total_seconds() print('多线程 耗时={}s'.format(delta)) #返回结果 # 2025-03-10 23:34:19,970 c2 5884 100000000 # 2025-03-10 23:34:20,961 c3 18784 100000000 # 2025-03-10 23:34:21,008 c4 13032 100000000 # 2025-03-10 23:34:21,025 c1 3396 100000000 # 多线程 耗时=19.013177s
注意,不要在代码中出现print等访问IO的语句。访问IO,线程阻塞,会释放GIL锁,其他线程被调度
程序1是单线程程序,所有calc()依次执行,根本就不是并发。在主线程内,函数串行执行。
程序2是多线程程序,calc()执行在不同的线程中,但是由于GIL的存在,线程的 执行变成了假并发。但是这些线程可以被调度到不同的CPU核心上执行,只不过 GIL让同一时间该进程只有一个线程被执行。
从两段程序测试的结果来看,CPython中多线程根本没有任何优势,和一个线程 执行时间相当。因为GIL的存在,尤其是像上面的计算密集型程序,和单线程串 行效果相当。这样,实际上就没有用上CPU多核心的优势。
多进程
多进程
由于Python的GIL全局解释器锁存在,多线程未必是CPU密集型程序的好的选择 多进程可以完全独立的进程环境中运行程序,可以较充分地利用多处理器 但是进程本身的隔离带来的数据不共享也是一个问题。而且线程比进程轻量级
multiprocessing
Process类
import multiprocessing import datetime import logging FORMAT = '%(asctime)s %(processName)s %(threadName)s %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) def calc(): sum = 0 for _ in range(1000000000): #10亿 sum += 1 logging.info(sum) #进程有没有返回值? return multiprocessing.current_process().name, sum if __name__ == '__main__': start = datetime.datetime.now() workers = [] #真并行,GIL有影响吗? for i in range(4): #启动了4个工作进程,用他们的主线程工作 p = multiprocessing.Process(target=calc, name='p-{}'.format(i)) workers.append(p) p.start() for p in workers: p.join() print(p.name, p.exitcode) #是返回值吗? delta = (datetime.datetime.now() - start).total_seconds() print('多进程 耗时={}s'.format(delta)) #返回结果 # 2025-03-10 23:50:08,891 p-1 MainThread 1000000000 # 2025-03-10 23:50:10,386 p-3 MainThread 1000000000 # 2025-03-10 23:50:12,125 p-2 MainThread 1000000000 # 2025-03-10 23:50:15,080 p-0 MainThread 1000000000 # p-0 0 # p-1 0 # p-2 0 # p-3 0 # 多进程 耗时=72.92779s
对于上面这个程序,在同一主机上运行时长的对比
- 使用单线程、多线程跑了4分钟多
- 多进程用了1分半
看到了多个进程都在使用CPU,这是真并行,而且进程库几乎没有学习难度。
注意:多进程代码一定要放在 __name__ = "main"= 下面执行。
名称 说明
pid 进程id exitcode 进程的退出状态码 terminate() 终止指定的进程
进程间同步
Python在进程间同步提供了和线程同步一样的类,使用的方法一样,使用的效果也类似。
不过,进程间代价要高于线程间,而且系统底层实现是不同的,只不过Python屏蔽了这些不同之处,让用户简单使用多进程。
multiprocessing还提供共享内存、服务器进程来共享数据,还提供了用于进程间通讯的Queue队列、Pipe管道。
通信方式不同
- 多进程就是启动多个解释器进程,进程间通信必须序列化、反序列化
数据的线程安全性问题
如果每个进程中没有实现多线程,GIL可以说没什么用了
进程池举例
multiprocessing.Pool 是进程池类
apply(self, func, args=(), kwds={}) 阻塞执行,导致主进程执行其他子进程就像一个个执行
apply_async(self, func, args=(), kwds={}, callback=None, error_callback=None) 与apply方法用法一致,非阻塞异步执行,得到结果后会执行回调
close() 关闭池,池不能再接受新的任务,所有任务完成后退出进程
terminate() 立即结束工作进程,不再处理未处理的任务
join() 主进程阻塞等待子进程的退出, join方法要在close或terminate之后使用
同步调用
- pool.apply 同步阻塞的方法,多进程串行
import multiprocessing import datetime import logging FORMAT = '%(asctime)s %(processName)s %(threadName)s %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) def calc(): sum = 0 for _ in range(100000000): #1亿 sum += 1 logging.info(sum) #进程有没有返回值? return multiprocessing.current_process().name, sum if __name__ == '__main__': start = datetime.datetime.now() pool = multiprocessing.Pool(4) for i in range(4): # 返回值,同步调用,注意观察CPU使用 ret = pool.apply(calc, ) #同步方法,阻塞的 logging.info('{1} --- {0}'.format(ret, type(ret))) pool.close() #不再接收新的进程 pool.join() delta = (datetime.datetime.now() - start).total_seconds() print('多进程池 同步 耗时={}s'.format(delta)) #返回结果 # 2025-03-11 00:35:09,261 SpawnPoolWorker-1 MainThread 100000000 # 2025-03-11 00:35:09,262 MainProcess MainThread <class 'tuple'> --- ('SpawnPoolWorker-1', 100000000) # 2025-03-11 00:35:14,554 SpawnPoolWorker-2 MainThread 100000000 # 2025-03-11 00:35:14,554 MainProcess MainThread <class 'tuple'> --- ('SpawnPoolWorker-2', 100000000) # 2025-03-11 00:35:19,411 SpawnPoolWorker-3 MainThread 100000000 # 2025-03-11 00:35:19,412 MainProcess MainThread <class 'tuple'> --- ('SpawnPoolWorker-3', 100000000) # 2025-03-11 00:35:24,256 SpawnPoolWorker-4 MainThread 100000000 # 2025-03-11 00:35:24,256 MainProcess MainThread <class 'tuple'> --- ('SpawnPoolWorker-4', 100000000) # 多进程池 同步 耗时=20.704703s
异步调用
- pool.aaply_async 异步非阻塞,真并行
import multiprocessing import datetime import logging FORMAT = '%(asctime)s %(processName)s %(threadName)s %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) def calc(): sum = 0 for _ in range(100000000): #1亿 sum += 1 logging.info(sum) #进程有没有返回值? return multiprocessing.current_process().name, sum if __name__ == '__main__': start = datetime.datetime.now() pool = multiprocessing.Pool(4) for i in range(4): # ret = pool.apply(calc, ) #同步方法,阻塞的 ret = pool.apply_async(calc) # 异步方法,没有阻塞 logging.info('{1} --- {0}'.format(ret, type(ret))) pool.close() #不再接收新的进程 pool.join() delta = (datetime.datetime.now() - start).total_seconds() print('多进程池 异步 耗时={}s'.format(delta)) #返回结果 # 2025-03-11 00:37:45,966 MainProcess MainThread <class 'multiprocessing.pool.ApplyResult'> --- <multiprocessing.pool.ApplyResult object at 0x000001F2E3C73770> # 2025-03-11 00:37:45,966 MainProcess MainThread <class 'multiprocessing.pool.ApplyResult'> --- <multiprocessing.pool.ApplyResult object at 0x000001F2E3D856D0> # 2025-03-11 00:37:45,966 MainProcess MainThread <class 'multiprocessing.pool.ApplyResult'> --- <multiprocessing.pool.ApplyResult object at 0x000001F2E3D85810> # 2025-03-11 00:37:45,966 MainProcess MainThread <class 'multiprocessing.pool.ApplyResult'> --- <multiprocessing.pool.ApplyResult object at 0x000001F2E3D949D0> # 2025-03-11 00:37:53,632 SpawnPoolWorker-1 MainThread 100000000 # 2025-03-11 00:37:53,739 SpawnPoolWorker-3 MainThread 100000000 # 2025-03-11 00:37:53,768 SpawnPoolWorker-4 MainThread 100000000 # 2025-03-11 00:37:54,047 SpawnPoolWorker-2 MainThread 100000000 # 多进程池 异步 耗时=8.231741s
import multiprocessing import datetime import logging FORMAT = '%(asctime)s %(processName)s %(threadName)s %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) def calc(): sum = 0 for _ in range(100000000): #1亿 sum += 1 logging.info(sum) #进程有没有返回值? return multiprocessing.current_process().name, sum if __name__ == '__main__': start = datetime.datetime.now() pool = multiprocessing.Pool(4) for i in range(4): # ret = pool.apply(calc, ) #同步方法,阻塞的 # 异步拿到的返回值是什么,回调起了什么作用 ret = pool.apply_async( calc, callback=lambda value: logging.info('**{}**'.format(value))) #异步方法,没有阻塞 logging.info('{1} --- {0}'.format(ret, type(ret))) pool.close() #不再接收新的进程 pool.join() delta = (datetime.datetime.now() - start).total_seconds() print('多进程池 异步 耗时={}s'.format(delta)) #返回结果 # 2025-03-11 00:46:50,627 MainProcess MainThread <class 'multiprocessing.pool.ApplyResult'> --- <multiprocessing.pool.ApplyResult object at 0x0000020A9F203770> # 2025-03-11 00:46:50,627 MainProcess MainThread <class 'multiprocessing.pool.ApplyResult'> --- <multiprocessing.pool.ApplyResult object at 0x0000020A9F2F56D0> # 2025-03-11 00:46:50,627 MainProcess MainThread <class 'multiprocessing.pool.ApplyResult'> --- <multiprocessing.pool.ApplyResult object at 0x0000020A9F2F5810> # 2025-03-11 00:46:50,627 MainProcess MainThread <class 'multiprocessing.pool.ApplyResult'> --- <multiprocessing.pool.ApplyResult object at 0x0000020A9F3048A0> # 2025-03-11 00:47:01,368 SpawnPoolWorker-1 MainThread 100000000 # 2025-03-11 00:47:01,369 MainProcess Thread-3 (_handle_results) **('SpawnPoolWorker-1', 100000000)** # 2025-03-11 00:47:02,295 SpawnPoolWorker-2 MainThread 100000000 # 2025-03-11 00:47:02,296 MainProcess Thread-3 (_handle_results) **('SpawnPoolWorker-2', 100000000)** # 2025-03-11 00:47:02,412 SpawnPoolWorker-4 MainThread 100000000 # 2025-03-11 00:47:02,413 MainProcess Thread-3 (_handle_results) **('SpawnPoolWorker-4', 100000000)** # 2025-03-11 00:47:02,915 SpawnPoolWorker-3 MainThread 100000000 # 2025-03-11 00:47:02,918 MainProcess Thread-3 (_handle_results) **('SpawnPoolWorker-3', 100000000)** # 多进程池 异步 耗时=12.441383s
多进程、多线程的选择
CPU密集型
- CPython中使用到了GIL,多线程的时候锁相互竞争,且多核优势不能发挥,选用Python多进程效率更高
IO密集型
- 在Python中适合是用多线程,可以减少多进程间IO的序列化开销。且在IO等待的时候,切换到其他线程继续执行,效率不错。
应用
请求/应答模型:WEB应用中常见的处理模型
master启动多个worker工作进程,一般和CPU数目相同。发挥多核优势。
worker工作进程中,往往需要操作网络IO和磁盘IO,启动多线程,提高并发处理能力。worker处理用户的请求,往往需要等待数据,处理完请求还要通过网络IO返回响应。
这就是nginx工作模式
Linux的特殊进程
在Linux/Unix中,通过父进程创建子进程
僵尸进程
一个进程使用了fork创建了子进程,如果子进程终止进入僵死状态,而父进程并 没有调用wait或者waitpid获取子进程的状态信息,那么子进程仍留下一个数据 结构保存在系统中,这种进程称为僵尸进程。
僵尸进程会占用一定的内存空间,还占用了进程号,所以一定要避免大量的僵尸进程产生。有很多方法可以避免僵尸进程。
孤儿进程
父进程退出,而它的子进程仍在运行,那么这些子进程就会成为孤儿进程。孤儿进程会被init进程(进程号为1)收养,并由init进程对它们完成状态收集工作。
init进程会循环调用wait这些孤儿进程,所以,孤儿进程没有什么危害。
守护进程
它是运行在后台的一种特殊进程。它独立于控制终端并周期性执行某种任务或等待处理某些事件。
守护进程的父进程是init进程,因为其父进程已经故意被终止掉了。
守护进程相对于普通的孤儿进程需要做一些特殊处理。
concurrent包(异步并行任务编程模块)
concurrent.futures包
3.2版本引入的模块
异步并行任务编程模块,提供一个高级的异步可执行的便利接口。
提供了2个池执行器
- ThreadPoolExecutor 异步调用的线程池的Executor
- ProcessPoolExecutor 异步调用的进程池的Executor
ThreadPoolExecutor对象
首先需要定义一个池的执行器对象,Executor类子类对象
ThreadPoolExecutor(max_workers=1) 池中至多创建max_workers个线程的池来同时异步执行,返回 Executor实例 submit(fn, *args, **kwargs) 提交执行的函数及其参数,返回Future类的实例 shutdown(wait=True 清理池
Future类
done() 如果调用被成功的取消或者执行完成,返回True, 否则False. 不阻塞。 cancelled() 如果调用被成功的取消,返回True running() 如果正在运行且不能被取消,返回True cancel() 尝试取消调用。如果已经执行且不能取消返回False,否则返回True。也就是PENDING状态的可以取消,就是提交了 的任务处于预备状态。 result(timeout=None) 取返回的结果,timeout为None,一直等待返回;timeout设置到期,抛出concurrent.futures.TimeoutError 异常 exception(timeout=None) 取返回的异常,timeout为None,一直等待返回;timeout设置到期,抛出concurrent.futures.TimeoutError 异常
ThreadPoolExecutor例子
from concurrent.futures import ThreadPoolExecutor import time import logging FORMAT = '%(asctime)s [%(processName)s %(process)d] [%(threadName)s %(thread)d]** %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) #基本使用 def worker(): logging.info('start~~~~') #正常执行的代码 time.sleep(5) logging.info('finished') executor = ThreadPoolExecutor(1) future = executor.submit(worker) #任务提交后立即启动 while not future.done(): #任务做完了吗 logging.info('Not done. {}'.format(future)) #查看future状态 time.sleep(1) executor.shutdown() print('=' * 30) #返回结果 # 2025-03-11 11:32:59,859 [MainProcess 26644] [ThreadPoolExecutor-0_0 5764]** start~~~~ # 2025-03-11 11:32:59,859 [MainProcess 26644] [MainThread 26988]** Not done. <Future at 0x1fe24476f90 state=running> # 2025-03-11 11:33:00,860 [MainProcess 26644] [MainThread 26988]** Not done. <Future at 0x1fe24476f90 state=running> # 2025-03-11 11:33:01,861 [MainProcess 26644] [MainThread 26988]** Not done. <Future at 0x1fe24476f90 state=running> # 2025-03-11 11:33:02,861 [MainProcess 26644] [MainThread 26988]** Not done. <Future at 0x1fe24476f90 state=running> # 2025-03-11 11:33:03,862 [MainProcess 26644] [MainThread 26988]** Not done. <Future at 0x1fe24476f90 state=running> # 2025-03-11 11:33:04,859 [MainProcess 26644] [ThreadPoolExecutor-0_0 5764]** finished # ==============================
from concurrent.futures import ThreadPoolExecutor import time import logging FORMAT = '%(asctime)s [%(processName)s %(process)d] [%(threadName)s %(thread)d]** %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) #基本使用 #Future实例的状态state: pending准备被执行; running正在被执行;finished执行完成;canncelled 成功取消 #done() 成功执行了或成功取消了finished, canncelled #状态running,不允许cancel def worker(): logging.info('start~~~~') #正常执行的代码 time.sleep(5) logging.info('finished') executor = ThreadPoolExecutor(1) future = executor.submit(worker) #任务提交后立即启动 f1 = executor.submit(worker) while not future.done(): #任务做完了吗 logging.info('Not done. {} | {}'.format(future, f1)) #查看future状态 time.sleep(1) f1.cancel() #取消 # future.cancel()#一旦running,不允许cancel while not f1.done(): #任务做完了吗 logging.info('Not done. {} | {}'.format(future, f1)) #查看future状态 time.sleep(1) print(future.done(), f1.done()) executor.shutdown() print('=' * 30) #返回结果 # 2025-03-11 14:21:56,842 [MainProcess 27540] [ThreadPoolExecutor-0_0 20428]** start~~~~ # 2025-03-11 14:21:56,842 [MainProcess 27540] [MainThread 24160]** Not done. <Future at 0x298c818af90 state=running> | <Future at 0x298c811f250 state=pending> # 2025-03-11 14:21:57,842 [MainProcess 27540] [MainThread 24160]** Not done. <Future at 0x298c818af90 state=running> | <Future at 0x298c811f250 state=cancelled> # 2025-03-11 14:21:58,843 [MainProcess 27540] [MainThread 24160]** Not done. <Future at 0x298c818af90 state=running> | <Future at 0x298c811f250 state=cancelled> # 2025-03-11 14:21:59,844 [MainProcess 27540] [MainThread 24160]** Not done. <Future at 0x298c818af90 state=running> | <Future at 0x298c811f250 state=cancelled> # 2025-03-11 14:22:00,845 [MainProcess 27540] [MainThread 24160]** Not done. <Future at 0x298c818af90 state=running> | <Future at 0x298c811f250 state=cancelled> # 2025-03-11 14:22:01,842 [MainProcess 27540] [ThreadPoolExecutor-0_0 20428]** finished # True True # ==============================
from concurrent.futures import ThreadPoolExecutor import time import logging FORMAT = '%(asctime)s [%(processName)s %(process)d] [%(threadName)s %(thread)d]** %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) #基本使用 #Future实例的状态state: pending准备被执行; running正在被执行;finished执行完成;canncelled 成功取消 #done() 成功执行了或成功取消了finished, canncelled,任务执行时有异常终止了也算finished #状态running,不允许cancel def worker(): logging.info('start~~~~') #正常执行的代码 time.sleep(2) logging.info('finished') def worker1(): logging.info('start~~~~') #正常执行的代码 time.sleep(5) 1/0 logging.info('finished') return 1234 executor = ThreadPoolExecutor(1) future = executor.submit(worker) #任务提交后立即启动 f1 = executor.submit(worker1) while not future.done(): #任务做完了吗 logging.info('Not done. {} | {}'.format(future, f1)) #查看future状态 time.sleep(1) # logging.info(f1.result(2)) #默认一直阻塞到done. 取返回的结果,等待2秒,超时了抛异常TimeoutError #result() 如果任务函数执行时线程内部有异常,没管。拿结果就会抛异常 #可以使用try捕获;先判断 e = f1.exception() logging.info("{} {}".format(type(e), e)) #默认一直阻塞到done. 取返回的异常,等待x秒,超时了抛异常TimeoutError #如果任务内部有异常,exception()可以正常取走该异常,拿到的是异常实例。 #如果任务正常执行结束,异常对象拿不到获取到一个None while not f1.done(): #任务做完了吗 logging.info('Not done. {} | {}'.format(future, f1)) #查看future状态 time.sleep(1) print(future.done(), f1.done()) executor.shutdown() print('=' * 30) #返回结果 # 2025-03-11 15:34:59,118 [MainProcess 6060] [ThreadPoolExecutor-0_0 32376]** start~~~~ # 2025-03-11 15:34:59,118 [MainProcess 6060] [MainThread 23788]** Not done. <Future at 0x1e3f7feef90 state=running> | <Future at 0x1e3f7f7f250 state=pending> # 2025-03-11 15:35:01,118 [MainProcess 6060] [ThreadPoolExecutor-0_0 32376]** finished # 2025-03-11 15:35:01,119 [MainProcess 6060] [ThreadPoolExecutor-0_0 32376]** start~~~~ # 2025-03-11 15:35:06,120 [MainProcess 6060] [MainThread 23788]** <class 'ZeroDivisionError'> division by zero # True True # ==============================
print(all([])) #一个False都没有,True print(all([0, 0, 0])) #False print(all([1])) #True print(all([1, 1, 1, 0])) #只要有一个False,就是False print('-' * 30) print(any([])) #一个都没有, False print(any([0, 0, 0, 1])) #只要有一个True,True
from concurrent.futures import ThreadPoolExecutor import time import logging import threading FORMAT = '%(asctime)s [%(processName)s %(process)d] [%(threadName)s %(thread)d]** %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) #基本使用 #Future实例的状态state: pending准备被执行; running正在被执行;finished执行完成;canncelled 成功取消 #done() 成功执行了或成功取消了finished, canncelled,任务执行时有异常终止了也算finished #状态running,不允许cancel def worker(n): logging.info('start~~~~') time.sleep(5) logging.info('finished') return n, n, n # 创建线程池,池容量为3 executor = ThreadPoolExecutor(3) time.sleep(1) print(threading.enumerate()) fs = [] for i in range(6): f = executor.submit(worker, i) #任务提交后立即启动 fs.append(f) print('*' * 30) while True: time.sleep(2) states = [f.done() for f in fs] if all(states): print('all done') for i in fs: print(i.done(), i.result()) break print(states) print(threading.enumerate()) #返回结果 # [<_MainThread(MainThread, started 10956)>] # 2025-03-11 16:10:01,236 [MainProcess 16524] [ThreadPoolExecutor-0_0 10592]** start~~~~ # 2025-03-11 16:10:01,237 [MainProcess 16524] [ThreadPoolExecutor-0_1 32156]** start~~~~ # 2025-03-11 16:10:01,237 [MainProcess 16524] [ThreadPoolExecutor-0_2 31680]** start~~~~ # ****************************** # [False, False, False, False, False, False] # [<_MainThread(MainThread, started 10956)>, <Thread(ThreadPoolExecutor-0_0, started 10592)>, <Thread(ThreadPoolExecutor-0_1, started 32156)>, <Thread(ThreadPoolExecutor-0_2, started 31680)>] # [False, False, False, False, False, False] # [<_MainThread(MainThread, started 10956)>, <Thread(ThreadPoolExecutor-0_0, started 10592)>, <Thread(ThreadPoolExecutor-0_1, started 32156)>, <Thread(ThreadPoolExecutor-0_2, started 31680)>] # 2025-03-11 16:10:06,237 [MainProcess 16524] [ThreadPoolExecutor-0_0 10592]** finished # 2025-03-11 16:10:06,238 [MainProcess 16524] [ThreadPoolExecutor-0_0 10592]** start~~~~ # 2025-03-11 16:10:06,239 [MainProcess 16524] [ThreadPoolExecutor-0_1 32156]** finished # 2025-03-11 16:10:06,240 [MainProcess 16524] [ThreadPoolExecutor-0_1 32156]** start~~~~ # 2025-03-11 16:10:06,239 [MainProcess 16524] [ThreadPoolExecutor-0_2 31680]** finished # 2025-03-11 16:10:06,240 [MainProcess 16524] [ThreadPoolExecutor-0_2 31680]** start~~~~ # [True, True, True, False, False, False] # [<_MainThread(MainThread, started 10956)>, <Thread(ThreadPoolExecutor-0_0, started 10592)>, <Thread(ThreadPoolExecutor-0_1, started 32156)>, <Thread(ThreadPoolExecutor-0_2, started 31680)>] # [True, True, True, False, False, False] # [<_MainThread(MainThread, started 10956)>, <Thread(ThreadPoolExecutor-0_0, started 10592)>, <Thread(ThreadPoolExecutor-0_1, started 32156)>, <Thread(ThreadPoolExecutor-0_2, started 31680)>] # 2025-03-11 16:10:11,239 [MainProcess 16524] [ThreadPoolExecutor-0_0 10592]** finished # 2025-03-11 16:10:11,240 [MainProcess 16524] [ThreadPoolExecutor-0_1 32156]** finished # 2025-03-11 16:10:11,241 [MainProcess 16524] [ThreadPoolExecutor-0_2 31680]** finished # all done # True (0, 0, 0) # True (1, 1, 1) # True (2, 2, 2) # True (3, 3, 3) # True (4, 4, 4) # True (5, 5, 5)
wait() 方法
from concurrent.futures import ThreadPoolExecutor, wait, Future import time import logging import threading FORMAT = '%(asctime)s [%(processName)s %(process)d] [%(threadName)s %(thread)d]** %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) def worker(n): logging.info('start~~~~') time.sleep(3 + i ) logging.info('finished') if n == 4: 1/0 return n, n, n # 创建线程池,池容量为3 executor = ThreadPoolExecutor(3) time.sleep(1) print(threading.enumerate()) fs = [] for i in range(6): f = executor.submit(worker, i) #任务提交后立即启动 fs.append(f) print('*' * 30) #wait ret = wait(fs) #一批futures print(type(ret), ret) print(ret.done) print(ret.not_done) print('=' * 30) for x in ret.done: # x:Future = x print(x.done()) if x.exception(): print(x.exception()) else: print(x.result()) #返回结果 # [<_MainThread(MainThread, started 29256)>] # 2025-03-11 16:42:34,242 [MainProcess 6280] [ThreadPoolExecutor-0_0 11956]** start~~~~ # 2025-03-11 16:42:34,243 [MainProcess 6280] [ThreadPoolExecutor-0_1 13216]** start~~~~ # 2025-03-11 16:42:34,243 [MainProcess 6280] [ThreadPoolExecutor-0_2 31820]** start~~~~ # ****************************** # 2025-03-11 16:42:38,243 [MainProcess 6280] [ThreadPoolExecutor-0_0 11956]** finished # 2025-03-11 16:42:38,244 [MainProcess 6280] [ThreadPoolExecutor-0_0 11956]** start~~~~ # 2025-03-11 16:42:39,243 [MainProcess 6280] [ThreadPoolExecutor-0_1 13216]** finished # 2025-03-11 16:42:39,244 [MainProcess 6280] [ThreadPoolExecutor-0_1 13216]** start~~~~ # 2025-03-11 16:42:42,244 [MainProcess 6280] [ThreadPoolExecutor-0_2 31820]** finished # 2025-03-11 16:42:42,245 [MainProcess 6280] [ThreadPoolExecutor-0_2 31820]** start~~~~ # 2025-03-11 16:42:46,245 [MainProcess 6280] [ThreadPoolExecutor-0_0 11956]** finished # 2025-03-11 16:42:47,244 [MainProcess 6280] [ThreadPoolExecutor-0_1 13216]** finished # 2025-03-11 16:42:50,246 [MainProcess 6280] [ThreadPoolExecutor-0_2 31820]** finished # <class 'concurrent.futures._base.DoneAndNotDoneFutures'> DoneAndNotDoneFutures(done={<Future at 0x2616c5d4830 state=finished returned tuple>, <Future at 0x2616c7fee40 state=finished returned tuple>, <Future at 0x2616c78f250 state=finished returned tuple>, <Future at 0x2616c811480 state=finished returned tuple>, <Future at 0x2616c78f890 state=finished returned tuple>, <Future at 0x2616c811940 state=finished raised ZeroDivisionError>}, not_done=set()) # {<Future at 0x2616c5d4830 state=finished returned tuple>, <Future at 0x2616c7fee40 state=finished returned tuple>, <Future at 0x2616c78f250 state=finished returned tuple>, <Future at 0x2616c811480 state=finished returned tuple>, <Future at 0x2616c78f890 state=finished returned tuple>, <Future at 0x2616c811940 state=finished raised ZeroDivisionError>} # set() # ============================== # True # (5, 5, 5) # True # (0, 0, 0) # True # (1, 1, 1) # True # (3, 3, 3) # True # (2, 2, 2) # True # division by zero
as_completed方法
from concurrent.futures import ThreadPoolExecutor, wait, Future, as_completed import time import logging import threading FORMAT = '%(asctime)s [%(processName)s %(process)d] [%(threadName)s %(thread)d]** %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) def worker(n): logging.info('start~~~~') time.sleep(n) logging.info('finished') return n, n, n # 创建线程池,池容量为3 executor = ThreadPoolExecutor(3) time.sleep(1) print(threading.enumerate()) fs = [] for i in (3, 6, 9, 15, 20, 25): f = executor.submit(worker, i) #任务提交后立即启动 fs.append(f) print('*' * 30) #as_completed # print(as_completed(fs), '+++') #生成器 for x in as_completed(fs): #阻塞到 logging.info('{} {} {}'.format(type(x), x, x.result())) #返回结果 # [<_MainThread(MainThread, started 3836)>] # 2025-03-11 17:04:33,893 [MainProcess 30716] [ThreadPoolExecutor-0_0 28676]** start~~~~ # 2025-03-11 17:04:33,894 [MainProcess 30716] [ThreadPoolExecutor-0_1 30972]** start~~~~ # 2025-03-11 17:04:33,894 [MainProcess 30716] [ThreadPoolExecutor-0_2 26244]** start~~~~ # ****************************** # 2025-03-11 17:04:36,894 [MainProcess 30716] [ThreadPoolExecutor-0_0 28676]** finished # 2025-03-11 17:04:36,894 [MainProcess 30716] [ThreadPoolExecutor-0_0 28676]** start~~~~ # 2025-03-11 17:04:36,895 [MainProcess 30716] [MainThread 3836]** <class 'concurrent.futures._base.Future'> <Future at 0x1dae708ee40 state=finished returned tuple> (3, 3, 3) # 2025-03-11 17:04:39,894 [MainProcess 30716] [ThreadPoolExecutor-0_1 30972]** finished # 2025-03-11 17:04:39,895 [MainProcess 30716] [ThreadPoolExecutor-0_1 30972]** start~~~~ # 2025-03-11 17:04:39,895 [MainProcess 30716] [MainThread 3836]** <class 'concurrent.futures._base.Future'> <Future at 0x1dae701f250 state=finished returned tuple> (6, 6, 6) # 2025-03-11 17:04:42,894 [MainProcess 30716] [ThreadPoolExecutor-0_2 26244]** finished # 2025-03-11 17:04:42,895 [MainProcess 30716] [ThreadPoolExecutor-0_2 26244]** start~~~~ # 2025-03-11 17:04:42,896 [MainProcess 30716] [MainThread 3836]** <class 'concurrent.futures._base.Future'> <Future at 0x1dae701f890 state=finished returned tuple> (9, 9, 9) # 2025-03-11 17:04:51,896 [MainProcess 30716] [ThreadPoolExecutor-0_0 28676]** finished # 2025-03-11 17:04:51,896 [MainProcess 30716] [MainThread 3836]** <class 'concurrent.futures._base.Future'> <Future at 0x1dae70a15b0 state=finished returned tuple> (15, 15, 15) # 2025-03-11 17:04:59,895 [MainProcess 30716] [ThreadPoolExecutor-0_1 30972]** finished # 2025-03-11 17:04:59,896 [MainProcess 30716] [MainThread 3836]** <class 'concurrent.futures._base.Future'> <Future at 0x1dae70a1a70 state=finished returned tuple> (20, 20, 20) # 2025-03-11 17:05:07,896 [MainProcess 30716] [ThreadPoolExecutor-0_2 26244]** finished # 2025-03-11 17:05:07,897 [MainProcess 30716] [MainThread 3836]** <class 'concurrent.futures._base.Future'> <Future at 0x1dae6e64830 state=finished returned tuple> (25, 25, 25)
用as_completed多些。
线程池一旦创建了线程,就不需要频繁清除
ProcessPoolExecutor对象
方法一样,就是使用多进程完成
ProcessPoolExecutor例子
from concurrent.futures import wait, Future, as_completed, ProcessPoolExecutor import time import logging import threading FORMAT = '%(asctime)s [%(processName)s %(process)d] [%(threadName)s %(thread)d]** %(message)s' logging.basicConfig(format=FORMAT, level=logging.INFO) def worker(n): logging.info('start~~~~') time.sleep(n) logging.info('finished') return n, n, n if __name__ == '__main__': executor = ProcessPoolExecutor(3) with executor: time.sleep(1) print(threading.enumerate()) fs = [] for i in (3, 6, 9, 15, 20, 25): f = executor.submit(worker, i) #任务提交后立即启动 fs.append(f) print('*' * 30) #as_completed # print(as_completed(fs), '+++') #生成器 for x in as_completed(fs): #阻塞到 logging.info('{} {} {}'.format(type(x), x, x.result())) # executor.shutdown() #返回结果 # [<_MainThread(MainThread, started 4196)>] # ****************************** # 2025-03-11 17:06:49,258 [SpawnProcess-1 25644] [MainThread 30572]** start~~~~ # 2025-03-11 17:06:49,270 [SpawnProcess-2 9548] [MainThread 31708]** start~~~~ # 2025-03-11 17:06:49,285 [SpawnProcess-3 29000] [MainThread 22776]** start~~~~ # 2025-03-11 17:06:52,259 [SpawnProcess-1 25644] [MainThread 30572]** finished # 2025-03-11 17:06:52,260 [SpawnProcess-1 25644] [MainThread 30572]** start~~~~ # 2025-03-11 17:06:52,260 [MainProcess 2824] [MainThread 4196]** <class 'concurrent.futures._base.Future'> <Future at 0x130612078c0 state=finished returned tuple> (3, 3, 3) # 2025-03-11 17:06:55,271 [SpawnProcess-2 9548] [MainThread 31708]** finished # 2025-03-11 17:06:55,271 [SpawnProcess-2 9548] [MainThread 31708]** start~~~~ # 2025-03-11 17:06:55,271 [MainProcess 2824] [MainThread 4196]** <class 'concurrent.futures._base.Future'> <Future at 0x1306120bed0 state=finished returned tuple> (6, 6, 6) # 2025-03-11 17:06:58,286 [SpawnProcess-3 29000] [MainThread 22776]** finished # 2025-03-11 17:06:58,287 [SpawnProcess-3 29000] [MainThread 22776]** start~~~~ # 2025-03-11 17:06:58,287 [MainProcess 2824] [MainThread 4196]** <class 'concurrent.futures._base.Future'> <Future at 0x13061370690 state=finished returned tuple> (9, 9, 9) # 2025-03-11 17:07:07,260 [SpawnProcess-1 25644] [MainThread 30572]** finished # 2025-03-11 17:07:07,261 [MainProcess 2824] [MainThread 4196]** <class 'concurrent.futures._base.Future'> <Future at 0x13061263820 state=finished returned tuple> (15, 15, 15) # 2025-03-11 17:07:15,271 [SpawnProcess-2 9548] [MainThread 31708]** finished # 2025-03-11 17:07:15,273 [MainProcess 2824] [MainThread 4196]** <class 'concurrent.futures._base.Future'> <Future at 0x13061263a80 state=finished returned tuple> (20, 20, 20) # 2025-03-11 17:07:23,288 [SpawnProcess-3 29000] [MainThread 22776]** finished # 2025-03-11 17:07:23,289 [MainProcess 2824] [MainThread 4196]** <class 'concurrent.futures._base.Future'> <Future at 0x13061344170 state=finished returned tuple> (25, 25, 25)
支持上下文管理
- concurrent.futures.ProcessPoolExecutor继承自concurrent.futures._base.Executor,而父类有__enter__ 、__exit__方法,支持上下文管理。可以使用with语句
- __exit__方法本质还是调用的shutdown(wait=True),就是一直阻塞到所有运行的任务完成
使用上下文改造上面的例子,增加返回计算的结果
总结
- 该库统一了线程池、进程池调用,简化了编程。
- 是Python简单的思想哲学的体现。
- 唯一的缺点:无法设置线程名称。但这都不值一提。